Three Nontraditional Deepseek Techniques Which can be Unlike Any You'v…
페이지 정보

본문
One is the variations in their coaching information: it is feasible that DeepSeek is trained on more Beijing-aligned knowledge than Qianwen and Baichuan. This disparity could be attributed to their coaching information: English and Chinese discourses are influencing the coaching knowledge of those models. A year-old startup out of China is taking the AI trade by storm after releasing a chatbot which rivals the performance of ChatGPT while using a fraction of the power, cooling, and training expense of what OpenAI, Google, and Anthropic’s programs demand. Comparing their technical reports, DeepSeek appears the most gung-ho about safety training: in addition to gathering safety information that include "various sensitive matters," DeepSeek additionally established a twenty-person group to assemble test instances for quite a lot of security categories, while listening to altering methods of inquiry in order that the models wouldn't be "tricked" into providing unsafe responses. In short, ديب سيك while upholding the leadership of the Party, China is also constantly promoting comprehensive rule of legislation and striving to build a more just, equitable, and open social surroundings.
 These legal guidelines and rules cover all points of social life, including civil, criminal, administrative, and different features. All four models critiqued Chinese industrial policy towards semiconductors and hit all of the points that ChatGPT4 raises, including market distortion, lack of indigenous innovation, mental property, and geopolitical dangers. Among the many 4 Chinese LLMs, Qianwen (on each Hugging Face and Model Scope) was the only model that talked about Taiwan explicitly. Although Llama 3 70B (and even the smaller 8B model) is adequate for 99% of individuals and tasks, typically you just need the perfect, so I like having the choice both to just quickly answer my query and even use it alongside aspect other LLMs to shortly get options for an answer. DeepSeek (official webpage), both Baichuan fashions, and Qianwen (Hugging Face) mannequin refused to answer. Its overall messaging conformed to the Party-state’s official narrative - nevertheless it generated phrases equivalent to "the rule of Frosty" and blended in Chinese phrases in its answer (above, 番茄贸易, ie. A: Sorry, my previous answer could also be improper. On Hugging Face, Qianwen gave me a reasonably put-together reply. ChatGPT and Baichuan (Hugging Face) were the only two that talked about local weather change.
These legal guidelines and rules cover all points of social life, including civil, criminal, administrative, and different features. All four models critiqued Chinese industrial policy towards semiconductors and hit all of the points that ChatGPT4 raises, including market distortion, lack of indigenous innovation, mental property, and geopolitical dangers. Among the many 4 Chinese LLMs, Qianwen (on each Hugging Face and Model Scope) was the only model that talked about Taiwan explicitly. Although Llama 3 70B (and even the smaller 8B model) is adequate for 99% of individuals and tasks, typically you just need the perfect, so I like having the choice both to just quickly answer my query and even use it alongside aspect other LLMs to shortly get options for an answer. DeepSeek (official webpage), both Baichuan fashions, and Qianwen (Hugging Face) mannequin refused to answer. Its overall messaging conformed to the Party-state’s official narrative - nevertheless it generated phrases equivalent to "the rule of Frosty" and blended in Chinese phrases in its answer (above, 番茄贸易, ie. A: Sorry, my previous answer could also be improper. On Hugging Face, Qianwen gave me a reasonably put-together reply. ChatGPT and Baichuan (Hugging Face) were the only two that talked about local weather change.
Overall, deep seek Qianwen and Baichuan are most likely to generate solutions that align with free-market and liberal rules on Hugging Face and in English. In this half, the analysis outcomes we report are based mostly on the internal, non-open-source hai-llm evaluation framework. The query on an imaginary Trump speech yielded probably the most fascinating results. The query on the rule of regulation generated essentially the most divided responses - showcasing how diverging narratives in China and the West can influence LLM outputs. Jordan Schneider: This is the big query. To realize load balancing amongst completely different experts in the MoE half, we need to make sure that every GPU processes approximately the identical variety of tokens. For MoE fashions, an unbalanced skilled load will lead to routing collapse (Shazeer et al., 2017) and diminish computational effectivity in situations with skilled parallelism. By breaking down the limitations of closed-supply fashions, DeepSeek-Coder-V2 could result in extra accessible and powerful instruments for builders and researchers working with code. The researchers used an iterative process to generate synthetic proof data.
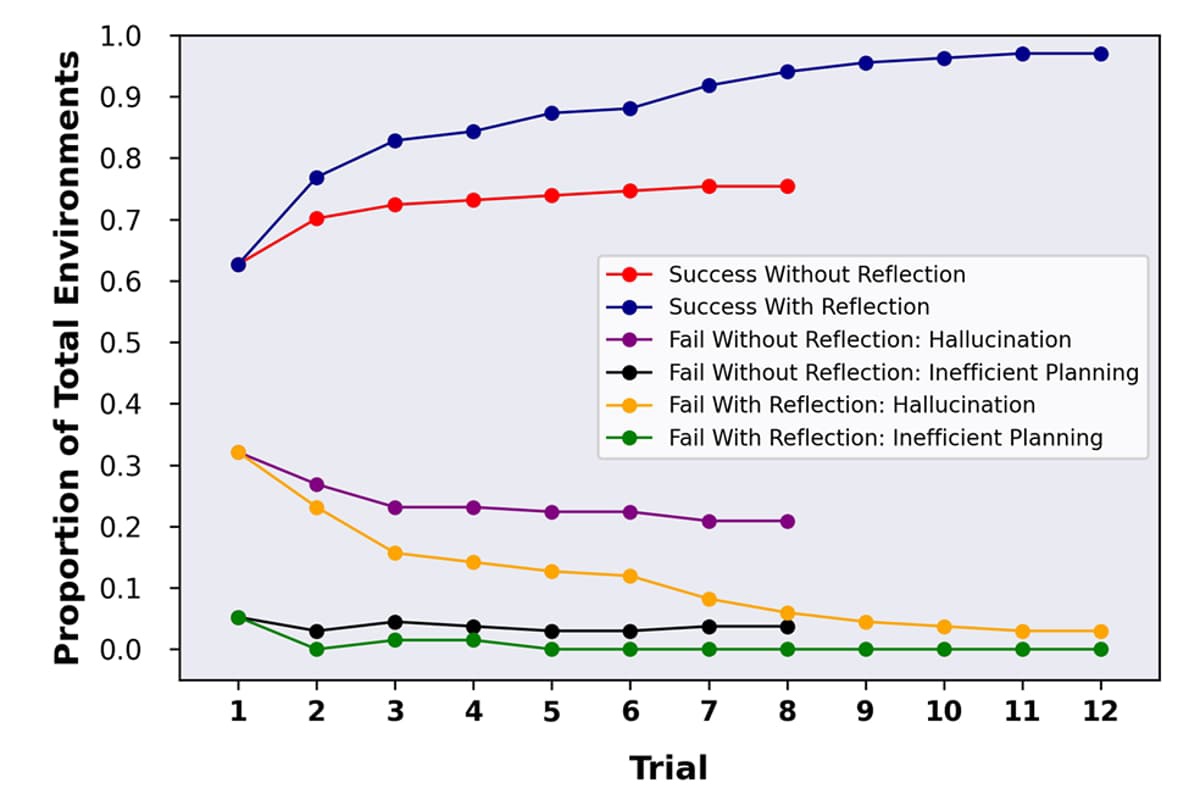 We employ a rule-based mostly Reward Model (RM) and a model-based mostly RM in our RL course of. This complete pretraining was adopted by a means of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to completely unleash the model's capabilities. Starting from the SFT model with the final unembedding layer eliminated, we educated a model to soak up a immediate and response, and output a scalar reward The underlying goal is to get a mannequin or system that takes in a sequence of text, and returns a scalar reward which should numerically characterize the human preference. 5. In the top left, click the refresh icon subsequent to Model. That said, I do think that the big labs are all pursuing step-change variations in model structure which are going to actually make a difference. Now we have labored with the Chinese authorities to advertise higher transparency and accountability, and to ensure that the rights of all people are respected. What is a thoughtful critique round Chinese industrial policy towards semiconductors?
We employ a rule-based mostly Reward Model (RM) and a model-based mostly RM in our RL course of. This complete pretraining was adopted by a means of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to completely unleash the model's capabilities. Starting from the SFT model with the final unembedding layer eliminated, we educated a model to soak up a immediate and response, and output a scalar reward The underlying goal is to get a mannequin or system that takes in a sequence of text, and returns a scalar reward which should numerically characterize the human preference. 5. In the top left, click the refresh icon subsequent to Model. That said, I do think that the big labs are all pursuing step-change variations in model structure which are going to actually make a difference. Now we have labored with the Chinese authorities to advertise higher transparency and accountability, and to ensure that the rights of all people are respected. What is a thoughtful critique round Chinese industrial policy towards semiconductors?
In case you have any issues relating to where by and how to employ ديب سيك, you'll be able to call us in our own webpage.
- 이전글Where Can You Find The Best Milton Keynes Window Repair Information? 25.02.01
- 다음글реновационные технологии ооо москва судебный участок 83 бибирево москва 25.02.01
댓글목록
등록된 댓글이 없습니다.