What it Takes to Compete in aI with The Latent Space Podcast
페이지 정보

본문
Chinese startup DeepSeek has built and launched DeepSeek-V2, a surprisingly highly effective language mannequin. These models signify a big development in language understanding and software. This highlights the necessity for extra superior data modifying strategies that may dynamically replace an LLM's understanding of code APIs. By spearheading the discharge of those state-of-the-artwork open-supply LLMs, DeepSeek site AI has marked a pivotal milestone in language understanding and AI accessibility, fostering innovation and broader applications in the sphere. The rapid growth of open-supply giant language fashions (LLMs) has been really remarkable. This paper presents a new benchmark called CodeUpdateArena to evaluate how nicely giant language fashions (LLMs) can replace their knowledge about evolving code APIs, a important limitation of current approaches. • This mannequin demonstrates the flexibility to purpose purely by means of RL but has drawbacks like poor readability and language mixing. This reward penalizes language mixing within the generated CoT, encouraging the model to persist with a single language. 7b-2: This model takes the steps and schema definition, translating them into corresponding SQL code. But there are nonetheless some particulars missing, such because the datasets and code used to train the fashions, so groups of researchers are actually making an attempt to piece these collectively.
 However, o1 still maintains the lead for me, which is also mirrored within the ARC AGI results, the place r1 compares with the decrease o1 fashions. These benefits can lead to higher outcomes for patients who can afford to pay for them. You possibly can tell it’s nonetheless a step behind. These fashions didn’t bear RL, which implies they still haven’t reached the higher bound of their intelligence. • During the RL, the researchers noticed what they referred to as "Aha moments"; that is when the model makes a mistake after which recognizes its error utilizing phrases like "There’s an Aha moment I can flag here" and corrects its mistake. With the DualPipe strategy, we deploy the shallowest layers (together with the embedding layer) and deepest layers (together with the output head) of the mannequin on the same PP rank. The censorship is in the applying layer. However, the hosted chat utility refuses to reply questions associated to CCP. You can get by means of most math questions utilizing r1.
However, o1 still maintains the lead for me, which is also mirrored within the ARC AGI results, the place r1 compares with the decrease o1 fashions. These benefits can lead to higher outcomes for patients who can afford to pay for them. You possibly can tell it’s nonetheless a step behind. These fashions didn’t bear RL, which implies they still haven’t reached the higher bound of their intelligence. • During the RL, the researchers noticed what they referred to as "Aha moments"; that is when the model makes a mistake after which recognizes its error utilizing phrases like "There’s an Aha moment I can flag here" and corrects its mistake. With the DualPipe strategy, we deploy the shallowest layers (together with the embedding layer) and deepest layers (together with the output head) of the mannequin on the same PP rank. The censorship is in the applying layer. However, the hosted chat utility refuses to reply questions associated to CCP. You can get by means of most math questions utilizing r1.
• In comparison with o1 on complicated reasoning and math? I'll solely use my complicated reasoning and math questions for this comparison. • The model receives rewards primarily based on the accuracy of its answers and its adherence to the required format (utilizing and tags for reasoning and answer). Ascend HiFloat8 format for deep studying. In essence, rather than counting on the identical foundational information (ie "the internet") utilized by OpenAI, DeepSeek used ChatGPT's distillation of the identical to provide its enter. The internet is abuzz with praise for r1’s remarkable creativity. This model blows older ones out of the water regarding creativity. It's natural to wonder if the model is closely censored in favour of China, but the good news is that the mannequin itself isn’t censored. Let’s see how good Deepseek r1 is. It will give an total impression of how good the model is compared to o1. It’s the second mannequin after O1 to get it right.
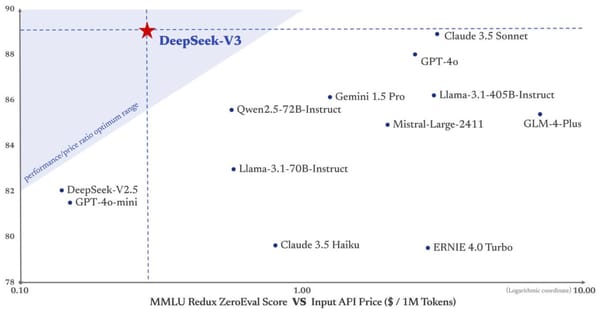 It took me nearly ten hits and trials to get it to say. Davidad: Nate Sores used to say that agents beneath time stress would study to raised handle their reminiscence hierarchy, thereby learn about "resources," thereby study power-in search of, and thereby be taught deception. Yes it is better than Claude 3.5(at present nerfed) and ChatGpt 4o at writing code. The timing of the assault coincided with DeepSeek's AI assistant app overtaking ChatGPT as the highest downloaded app on the Apple App Store. The discharge of China's new DeepSeek AI-powered chatbot app has rocked the expertise industry. But does Deepseek r1 censors? From my expertise enjoying with Deepseek r1, it has been an incredible reasoner; it positively felt better than o1-preview. In actual fact, this model is a powerful argument that synthetic coaching knowledge can be used to great impact in building AI models. DeepSeek claimed that they'd spent simply $5.5 million training V3. I usually pick a most recent LeetCode Hard question to reduce the possibilities of this being within the coaching set. It’s a difficult query for an LLM, and R1 utterly nails it. It’s backed by High-Flyer Capital Management, a Chinese quantitative hedge fund that makes use of AI to inform its trading decisions.
It took me nearly ten hits and trials to get it to say. Davidad: Nate Sores used to say that agents beneath time stress would study to raised handle their reminiscence hierarchy, thereby learn about "resources," thereby study power-in search of, and thereby be taught deception. Yes it is better than Claude 3.5(at present nerfed) and ChatGpt 4o at writing code. The timing of the assault coincided with DeepSeek's AI assistant app overtaking ChatGPT as the highest downloaded app on the Apple App Store. The discharge of China's new DeepSeek AI-powered chatbot app has rocked the expertise industry. But does Deepseek r1 censors? From my expertise enjoying with Deepseek r1, it has been an incredible reasoner; it positively felt better than o1-preview. In actual fact, this model is a powerful argument that synthetic coaching knowledge can be used to great impact in building AI models. DeepSeek claimed that they'd spent simply $5.5 million training V3. I usually pick a most recent LeetCode Hard question to reduce the possibilities of this being within the coaching set. It’s a difficult query for an LLM, and R1 utterly nails it. It’s backed by High-Flyer Capital Management, a Chinese quantitative hedge fund that makes use of AI to inform its trading decisions.
In the event you liked this short article and you want to receive guidance concerning ديب سيك i implore you to visit the web site.
- 이전글لسان العرب : طاء - 25.02.07
- 다음글Patio Door Track Repair Tools To Streamline Your Daily Life Patio Door Track Repair Trick Every Person Should Be Able To 25.02.07
댓글목록
등록된 댓글이 없습니다.