The Stuff About Deepseek Chatgpt You In all probability Hadn't Thought…
페이지 정보

본문
Chinese AI start-up DeepSeek has rocked the US inventory market after demonstrating breakthrough synthetic intelligence models that offer comparable performance to the world’s best chatbots at seemingly a fraction of the associated fee. Huawei is now the kind of vanguard of that new model where Huawei is partnering with state-owned enterprises like SMIC or Research Institutes like the China Academy of Sciences to work together to take non-public market orientation, business process, R&D, administration skills and the good tech popping out of the labs and push ahead. However, DeepSeek has its shortcomings - like all other Chinese AI fashions, it self-censors on subjects deemed sensitive in China. 4-9b-chat by THUDM: A very fashionable Chinese chat mannequin I couldn’t parse much from r/LocalLLaMA on. However, contemplating it is based on Qwen and how great each the QwQ 32B and Qwen 72B models carry out, I had hoped QVQ being both 72B and reasoning would have had way more of an impression on its basic efficiency. Additionally, the focus is more and more on advanced reasoning tasks reasonably than pure factual knowledge. Separately, by batching, the processing of multiple tasks without delay, and leveraging the cloud, this model further lowers prices and hastens performance, making it even more accessible for a wide range of users.
 Falcon3 10B Instruct did surprisingly properly, scoring 61%. Most small fashions do not even make it previous the 50% threshold to get onto the chart in any respect (like IBM Granite 8B, which I additionally tested nevertheless it didn't make the lower). Falcon3 10B even surpasses Mistral Small which at 22B is over twice as huge. In 2023, Mistral AI openly launched its Mixtral 8x7B mannequin which was on par with the advanced fashions of the time. However, closed-supply fashions adopted many of the insights from Mixtral 8x7b and received higher. QwQ 32B did so a lot better, but even with 16K max tokens, QVQ 72B didn't get any better through reasoning more. 71%, which is a little bit higher than the unquantized (!) Llama 3.1 70B Instruct and almost on par with gpt-4o-2024-11-20! 4-bit, extraordinarily near the unquantized Llama 3.1 70B it is primarily based on. Llama 3.1 Nemotron 70B Instruct is the oldest mannequin on this batch, at three months old it's mainly ancient in LLM phrases. Along side knowledgeable parallelism, we use knowledge parallelism for all other layers, where each GPU stores a duplicate of the model and optimizer and processes a special chunk of knowledge. • Deploy on a client GPU (RTX 4090) as an alternative of paying for cloud servers.
Falcon3 10B Instruct did surprisingly properly, scoring 61%. Most small fashions do not even make it previous the 50% threshold to get onto the chart in any respect (like IBM Granite 8B, which I additionally tested nevertheless it didn't make the lower). Falcon3 10B even surpasses Mistral Small which at 22B is over twice as huge. In 2023, Mistral AI openly launched its Mixtral 8x7B mannequin which was on par with the advanced fashions of the time. However, closed-supply fashions adopted many of the insights from Mixtral 8x7b and received higher. QwQ 32B did so a lot better, but even with 16K max tokens, QVQ 72B didn't get any better through reasoning more. 71%, which is a little bit higher than the unquantized (!) Llama 3.1 70B Instruct and almost on par with gpt-4o-2024-11-20! 4-bit, extraordinarily near the unquantized Llama 3.1 70B it is primarily based on. Llama 3.1 Nemotron 70B Instruct is the oldest mannequin on this batch, at three months old it's mainly ancient in LLM phrases. Along side knowledgeable parallelism, we use knowledge parallelism for all other layers, where each GPU stores a duplicate of the model and optimizer and processes a special chunk of knowledge. • Deploy on a client GPU (RTX 4090) as an alternative of paying for cloud servers.
Second, with local fashions running on shopper hardware, there are sensible constraints around computation time - a single run already takes a number of hours with bigger models, and i generally conduct a minimum of two runs to ensure consistency. Unlike typical benchmarks that solely report single scores, I conduct multiple take a look at runs for every mannequin to seize efficiency variability. The benchmarks for this examine alone required over 70 88 hours of runtime. As someone who has been using ChatGPT because it got here out in November 2022, after a couple of hours of testing DeepSeek, I discovered myself lacking lots of the features OpenAI has added over the previous two years. I truly had to rewrite two business projects from Vite to Webpack as a result of once they went out of PoC part and began being full-grown apps with extra code and extra dependencies, build was eating over 4GB of RAM (e.g. that is RAM restrict in Bitbucket Pipelines).
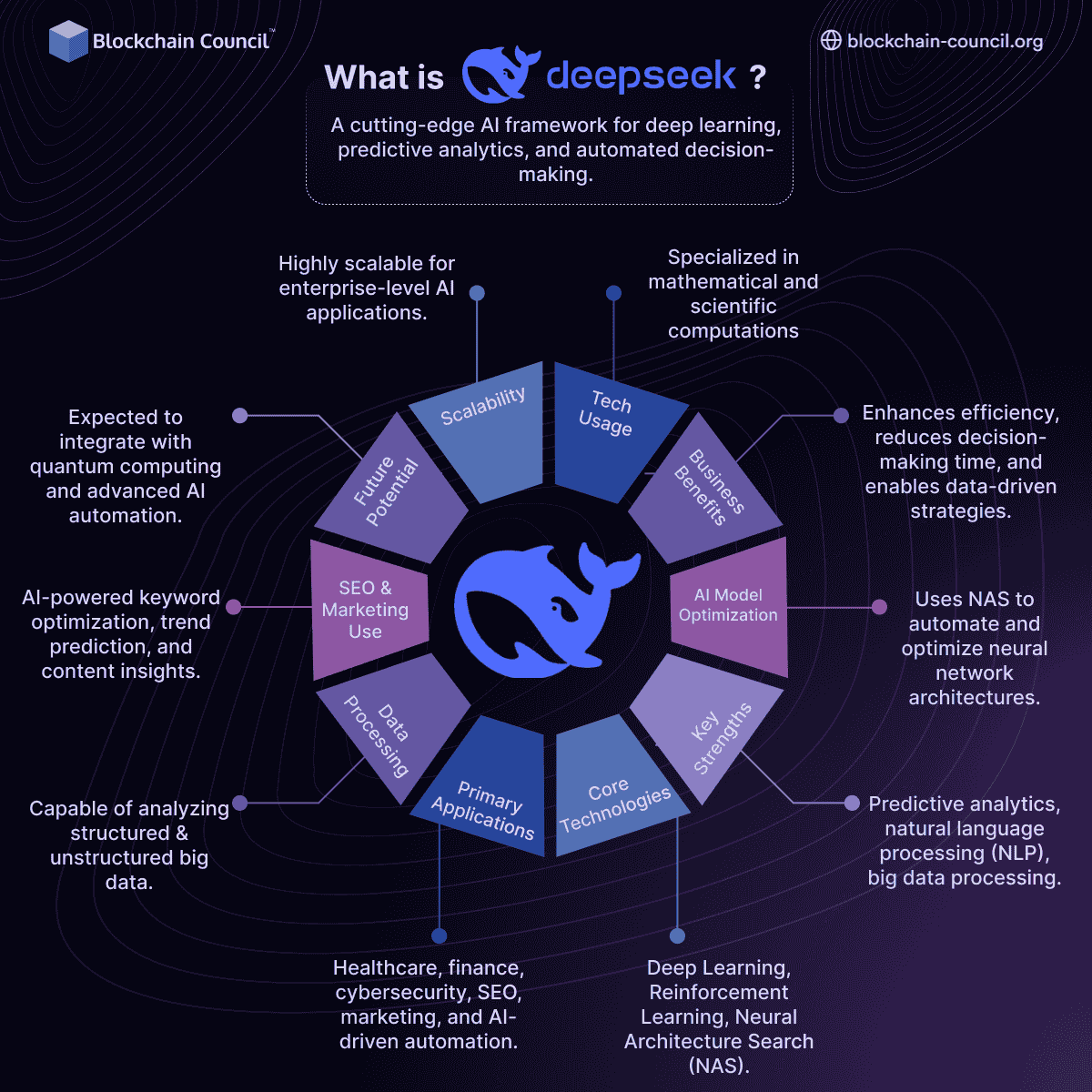 Developers world wide are already experimenting with DeepSeek’s software to construct instruments with it. Global know-how stocks tumbled overnight as hype around DeepSeek’s innovation snowballed and traders began to digest the implications for its US-based mostly rivals and their hardware suppliers. Despite Washington’s bid to stall China’s advances in AI, DeepSeek’s progress suggests Chinese engineers worked across the restrictions. Despite matching general performance, they offered completely different solutions on 101 questions! After analyzing ALL results for unsolved questions throughout my examined models, solely 10 out of 410 (2.44%) remained unsolved. The analysis of unanswered questions yielded equally fascinating results: Among the top native fashions (Athene-V2-Chat, DeepSeek-V3, Qwen2.5-72B-Instruct, and QwQ-32B-Preview), solely 30 out of 410 questions (7.32%) received incorrect answers from all fashions. For my benchmarks, I currently limit myself to the computer Science class with its 410 questions. The MMLU-Pro benchmark is a complete analysis of giant language fashions across varied categories, including computer science, mathematics, physics, chemistry, and extra. SenseTime, for example, is undisputedly one of many world leaders in computer vision AI and claims to have achieved annual income development of four hundred % for three consecutive years.
Developers world wide are already experimenting with DeepSeek’s software to construct instruments with it. Global know-how stocks tumbled overnight as hype around DeepSeek’s innovation snowballed and traders began to digest the implications for its US-based mostly rivals and their hardware suppliers. Despite Washington’s bid to stall China’s advances in AI, DeepSeek’s progress suggests Chinese engineers worked across the restrictions. Despite matching general performance, they offered completely different solutions on 101 questions! After analyzing ALL results for unsolved questions throughout my examined models, solely 10 out of 410 (2.44%) remained unsolved. The analysis of unanswered questions yielded equally fascinating results: Among the top native fashions (Athene-V2-Chat, DeepSeek-V3, Qwen2.5-72B-Instruct, and QwQ-32B-Preview), solely 30 out of 410 questions (7.32%) received incorrect answers from all fashions. For my benchmarks, I currently limit myself to the computer Science class with its 410 questions. The MMLU-Pro benchmark is a complete analysis of giant language fashions across varied categories, including computer science, mathematics, physics, chemistry, and extra. SenseTime, for example, is undisputedly one of many world leaders in computer vision AI and claims to have achieved annual income development of four hundred % for three consecutive years.
- 이전글Why ADHD Assessment Private Is More Risky Than You Think 25.02.10
- 다음글7 Simple Tricks To Rocking Your French Bulldog Puppies 25.02.10
댓글목록
등록된 댓글이 없습니다.