Are You Struggling With Deepseek? Let's Chat
페이지 정보

본문
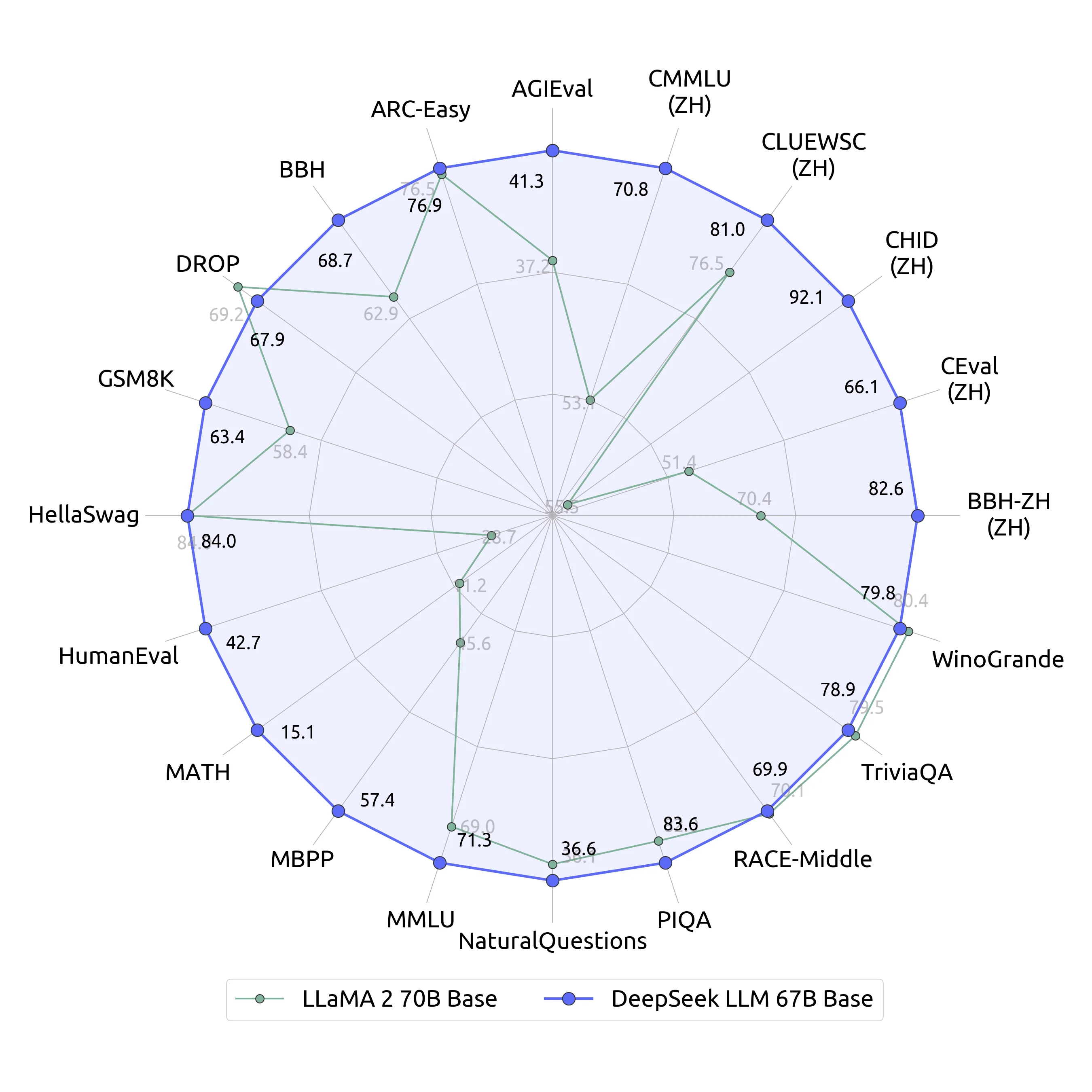
The DeepSeek iOS application additionally integrates the Intercom iOS SDK and data is exchanged between the two platforms. However, there are a number of the reason why corporations might send data to servers in the current country together with efficiency, regulatory, or extra nefariously to mask where the info will in the end be sent or processed. Will macroeconimcs restrict the developement of AI? Traditional backlink strategies depend on manual outreach, but DeepSeek will automate, predict, and optimize link-constructing efforts. To maximise the potential of DeepSeek for Seo success, it is essential to leverage its features effectively throughout keyword research, content material creation, optimization, technical Seo, backlink building, and efficiency monitoring. Furthermore, we enhance models’ performance on the contrast units by making use of LIT to augment the training knowledge, with out affecting efficiency on the unique data. One of many standout features of DeepSeek’s LLMs is the 67B Base version’s distinctive efficiency compared to the Llama2 70B Base, showcasing superior capabilities in reasoning, شات ديب سيك coding, mathematics, and Chinese comprehension.
 LLama(Large Language Model Meta AI)3, ديب سيك شات the next era of Llama 2, Trained on 15T tokens (7x more than Llama 2) by Meta is available in two sizes, the 8b and 70b model. For RTX 4090, you'll be able to run up to DeepSeek R1 32B. Larger models like DeepSeek R1 70B require a number of GPUs. Eight GB of RAM out there to run the 7B fashions, sixteen GB to run the 13B models, and 32 GB to run the 33B fashions. Ollama lets us run massive language models locally, it comes with a fairly simple with a docker-like cli interface to start, stop, pull and record processes. The company aims to create environment friendly AI assistants that may be integrated into various functions by means of simple API calls and a person-pleasant chat interface. Even discussing a fastidiously scoped set of dangers can raise difficult, unsolved technical questions. Conclusion: The impression of podcasts discussing the Russia-Ukraine warfare on viewers and expert viewpoints depends largely on the podcastâs approach and the audienceâs openness to new data. However several developments may be noticed: Approximately 60-70% of podcasts in Western media are pro-Ukraine; roughly 10-20% are professional-Russia, mostly discovered on Russian platforms or niche channels. It then checks whether or not the end of the phrase was discovered and returns this data.
LLama(Large Language Model Meta AI)3, ديب سيك شات the next era of Llama 2, Trained on 15T tokens (7x more than Llama 2) by Meta is available in two sizes, the 8b and 70b model. For RTX 4090, you'll be able to run up to DeepSeek R1 32B. Larger models like DeepSeek R1 70B require a number of GPUs. Eight GB of RAM out there to run the 7B fashions, sixteen GB to run the 13B models, and 32 GB to run the 33B fashions. Ollama lets us run massive language models locally, it comes with a fairly simple with a docker-like cli interface to start, stop, pull and record processes. The company aims to create environment friendly AI assistants that may be integrated into various functions by means of simple API calls and a person-pleasant chat interface. Even discussing a fastidiously scoped set of dangers can raise difficult, unsolved technical questions. Conclusion: The impression of podcasts discussing the Russia-Ukraine warfare on viewers and expert viewpoints depends largely on the podcastâs approach and the audienceâs openness to new data. However several developments may be noticed: Approximately 60-70% of podcasts in Western media are pro-Ukraine; roughly 10-20% are professional-Russia, mostly discovered on Russian platforms or niche channels. It then checks whether or not the end of the phrase was discovered and returns this data.
The search technique starts at the basis node and follows the little one nodes until it reaches the end of the phrase or runs out of characters. If a duplicate phrase is tried to be inserted, the operate returns without inserting anything. Factorial Function: The factorial function is generic over any kind that implements the Numeric trait. Numeric Trait: This trait defines basic operations for numeric varieties, including multiplication and a technique to get the worth one. This code creates a basic Trie information construction and offers methods to insert words, search for phrases, and examine if a prefix is current in the Trie. "Despite their apparent simplicity, these problems often contain complicated solution methods, making them wonderful candidates for constructing proof knowledge to improve theorem-proving capabilities in Large Language Models (LLMs)," the researchers write. We talk about methodological points and difficulties with making this work, after which illustrate the overall idea with a case research in unsupervised machine translation, before concluding with a discussion on the relation to multimodal pretraining. As new datasets, pretraining protocols, and probes emerge, we imagine that probing-throughout-time analyses can help researchers understand the complex, intermingled learning that these models bear and guide us towards more environment friendly approaches that accomplish needed learning quicker.
Recent work applied several probes to intermediate coaching phases to observe the developmental means of a large-scale model (Chiang et al., 2020). Following this effort, we systematically answer a query: for numerous sorts of information a language mannequin learns, when during (pre)coaching are they acquired? Using RoBERTa as a case research, we find: linguistic information is acquired fast, stably, and robustly across domains. Cost: Since the open supply mannequin does not have a worth tag, we estimate the cost by: We use the Azure ND40rs-v2 occasion (8X V100 GPU) April 2024 pay-as-you-go pricing in the associated fee calculation. Maybe next gen fashions are gonna have agentic capabilities in weights. So the notion that related capabilities as America’s most highly effective AI fashions might be achieved for such a small fraction of the fee - and on less capable chips - represents a sea change within the industry’s understanding of how much funding is required in AI. DeepSeek represents China’s efforts to construct up home scientific and technological capabilities and to innovate past that. The newest in this pursuit is DeepSeek Chat, from China’s DeepSeek AI. Competing exhausting on the AI front, China’s DeepSeek AI introduced a brand new LLM known as DeepSeek Chat this week, which is more highly effective than any other present LLM.
If you are you looking for more info on ديب سيك شات have a look at the page.
- 이전글NFL Odds, Football Betting Strains & Point Spreads 25.02.13
- 다음글Cause Of Hair Reduction In Women - The Role Of Dht & Sebum 25.02.13
댓글목록
등록된 댓글이 없습니다.