?The Deep Roots of DeepSeek: how it all Began
페이지 정보

본문
 DeepSeek V3: Trained on 14.Eight trillion tokens with advanced reinforcement studying and data distillation for effectivity. This strategy allows models to handle completely different aspects of knowledge extra effectively, improving efficiency and scalability in large-scale duties. However, it is very important keep in mind that the app could request more entry to data. However, it’s important to notice that if you use DeepSeek’s cloud-primarily based providers, your information may be stored on servers in China, which raises privacy issues for some users. DeepSeek-V2 introduced one other of DeepSeek’s innovations - Multi-Head Latent Attention (MLA), a modified consideration mechanism for Transformers that enables faster info processing with less reminiscence utilization. This approach fosters collaborative innovation and permits for broader accessibility throughout the AI community. Liang Wenfeng: Innovation is expensive and inefficient, sometimes accompanied by waste. Liang stated in July. DeepSeek CEO Liang Wenfeng, additionally the founding father of High-Flyer - a Chinese quantitative fund and DeepSeek’s main backer - lately met with Chinese Premier Li Qiang, where he highlighted the challenges Chinese corporations face resulting from U.S. Liang Wenfeng: Our core workforce, including myself, initially had no quantitative experience, which is kind of unique. Reinforcement Learning: The mannequin utilizes a more refined reinforcement learning strategy, including Group Relative Policy Optimization (GRPO), which uses suggestions from compilers and test circumstances, and a discovered reward model to advantageous-tune the Coder.
DeepSeek V3: Trained on 14.Eight trillion tokens with advanced reinforcement studying and data distillation for effectivity. This strategy allows models to handle completely different aspects of knowledge extra effectively, improving efficiency and scalability in large-scale duties. However, it is very important keep in mind that the app could request more entry to data. However, it’s important to notice that if you use DeepSeek’s cloud-primarily based providers, your information may be stored on servers in China, which raises privacy issues for some users. DeepSeek-V2 introduced one other of DeepSeek’s innovations - Multi-Head Latent Attention (MLA), a modified consideration mechanism for Transformers that enables faster info processing with less reminiscence utilization. This approach fosters collaborative innovation and permits for broader accessibility throughout the AI community. Liang Wenfeng: Innovation is expensive and inefficient, sometimes accompanied by waste. Liang stated in July. DeepSeek CEO Liang Wenfeng, additionally the founding father of High-Flyer - a Chinese quantitative fund and DeepSeek’s main backer - lately met with Chinese Premier Li Qiang, where he highlighted the challenges Chinese corporations face resulting from U.S. Liang Wenfeng: Our core workforce, including myself, initially had no quantitative experience, which is kind of unique. Reinforcement Learning: The mannequin utilizes a more refined reinforcement learning strategy, including Group Relative Policy Optimization (GRPO), which uses suggestions from compilers and test circumstances, and a discovered reward model to advantageous-tune the Coder.
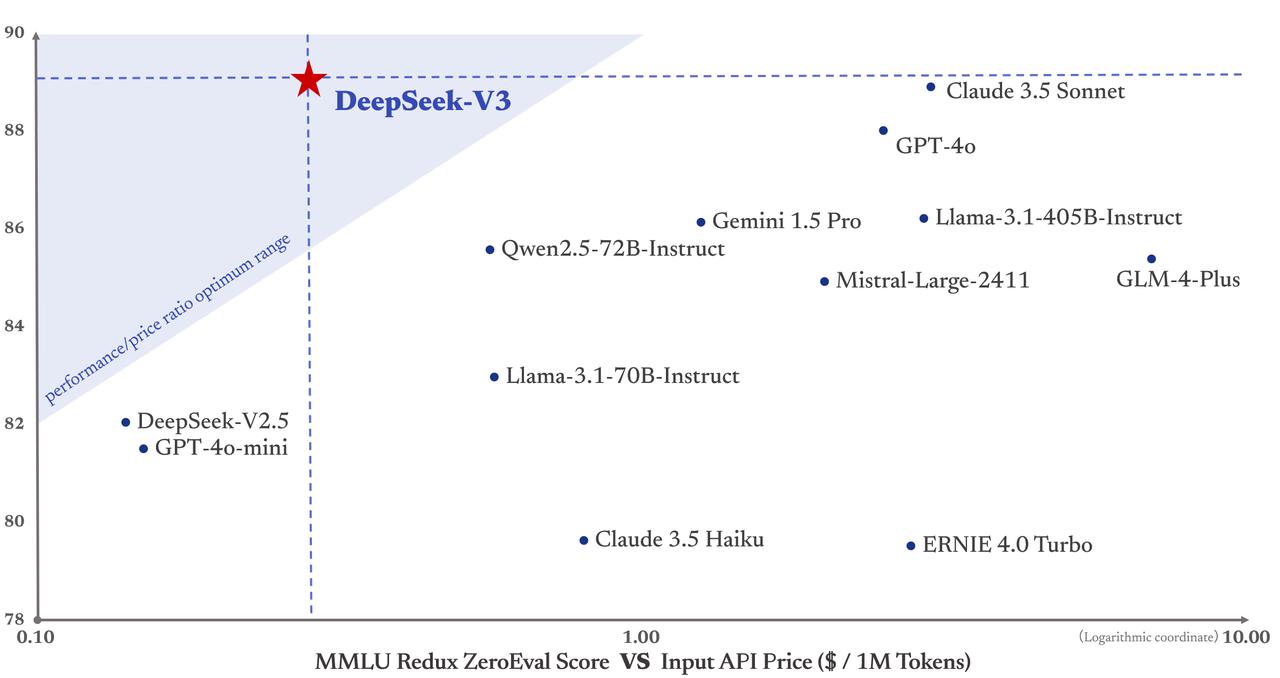 The bigger mannequin is extra powerful, and its structure is based on DeepSeek's MoE strategy with 21 billion "energetic" parameters. This mannequin is especially helpful for builders working on initiatives that require subtle AI capabilities, akin to chatbots, virtual assistants, and automatic content era.Free DeepSeek v3-Coder is an AI model designed to assist with coding. Multi-Head Latent Attention (MLA): In a Transformer, attention mechanisms assist the model concentrate on the most relevant components of the input. DeepSeek’s models focus on effectivity, open-source accessibility, multilingual capabilities, and value-effective AI coaching while maintaining robust performance. No matter Open-R1’s success, nonetheless, Bakouch says DeepSeek’s impact goes properly past the open AI neighborhood. Initially, DeepSeek created their first mannequin with architecture just like other open models like LLaMA, aiming to outperform benchmarks. But, like many fashions, it faced challenges in computational effectivity and scalability. This means they successfully overcame the earlier challenges in computational effectivity! Meaning an organization primarily based in Singapore might order chips from Nvidia, with their billing handle marked as such, however have them delivered to a different nation.
The bigger mannequin is extra powerful, and its structure is based on DeepSeek's MoE strategy with 21 billion "energetic" parameters. This mannequin is especially helpful for builders working on initiatives that require subtle AI capabilities, akin to chatbots, virtual assistants, and automatic content era.Free DeepSeek v3-Coder is an AI model designed to assist with coding. Multi-Head Latent Attention (MLA): In a Transformer, attention mechanisms assist the model concentrate on the most relevant components of the input. DeepSeek’s models focus on effectivity, open-source accessibility, multilingual capabilities, and value-effective AI coaching while maintaining robust performance. No matter Open-R1’s success, nonetheless, Bakouch says DeepSeek’s impact goes properly past the open AI neighborhood. Initially, DeepSeek created their first mannequin with architecture just like other open models like LLaMA, aiming to outperform benchmarks. But, like many fashions, it faced challenges in computational effectivity and scalability. This means they successfully overcame the earlier challenges in computational effectivity! Meaning an organization primarily based in Singapore might order chips from Nvidia, with their billing handle marked as such, however have them delivered to a different nation.
This implies V2 can higher understand and handle extensive codebases. This normally involves storing rather a lot of data, Key-Value cache or or KV cache, briefly, which could be slow and reminiscence-intensive. DeepSeek-V2 introduces Multi-Head Latent Attention (MLA), a modified consideration mechanism that compresses the KV cache into a much smaller kind. DeepSeek-V2 is a state-of-the-artwork language mannequin that makes use of a Transformer structure combined with an innovative MoE system and a specialized consideration mechanism called Multi-Head Latent Attention (MLA). Transformer structure: At its core, DeepSeek-V2 makes use of the Transformer architecture, which processes text by splitting it into smaller tokens (like phrases or subwords) after which makes use of layers of computations to understand the relationships between these tokens. By leveraging reinforcement studying and environment friendly architectures like MoE, DeepSeek significantly reduces the computational assets required for coaching, leading to lower costs. While much consideration within the AI neighborhood has been targeted on fashions like LLaMA and Mistral, DeepSeek has emerged as a significant player that deserves nearer examination. Their revolutionary approaches to consideration mechanisms and the Mixture-of-Experts (MoE) method have led to impressive effectivity features.
This led the DeepSeek Ai Chat AI team to innovate further and develop their own approaches to unravel these existing problems. Their preliminary attempt to beat the benchmarks led them to create fashions that have been somewhat mundane, just like many others. Testing DeepSeek-Coder-V2 on numerous benchmarks shows that DeepSeek-Coder-V2 outperforms most fashions, including Chinese competitors. Excels in both English and Chinese language tasks, in code generation and mathematical reasoning. DeepSeek is a powerful AI language model that requires varying system specs depending on the platform it runs on. However, regardless of its sophistication, the model has crucial shortcomings. The hiring spree follows the speedy success of its R1 mannequin, which has positioned itself as a robust rival to OpenAI’s ChatGPT despite operating on a smaller budget. This strategy set the stage for a sequence of rapid model releases. The freshest model, released by Deepseek Online chat in August 2024, is an optimized model of their open-supply mannequin for theorem proving in Lean 4, DeepSeek-Prover-V1.5.
- 이전글Beware Of These "Trends" About Buy A2 Driving License Online 25.02.24
- 다음글The 10 Scariest Things About Automatic Vacuum Cleaner And Mop 25.02.24
댓글목록
등록된 댓글이 없습니다.