Featured10 Must-Try DeepSeek R1 Prompts to Remodel Your Finance Workfl…
페이지 정보

본문
 The DeepSeek fashions, typically missed compared to GPT-4o and Claude 3.5 Sonnet, have gained respectable momentum in the past few months. The company's latest fashions, DeepSeek-V3 and DeepSeek-R1, have additional solidified its place as a disruptive drive. Welcome to this subject of Recode China AI, your go-to publication for the newest AI information and analysis in China. Nvidia competitor Intel has recognized sparsity as a key avenue of research to change the state-of-the-art in the field for many years. The meteoric rise of DeepSeek when it comes to usage and popularity triggered a inventory market sell-off on Jan. 27, 2025, as buyers cast doubt on the worth of large AI distributors based in the U.S., including Nvidia. Microsoft, Meta Platforms, Oracle, Broadcom and other tech giants additionally saw significant drops as investors reassessed AI valuations. Why are traders frightened about DeepSeek? Why Choose DeepSeek Windows Download? That's certainly one of the principle reasons why the U.S. It's like buying a piano for the home; one can afford it, and there's a group eager to play music on it.
The DeepSeek fashions, typically missed compared to GPT-4o and Claude 3.5 Sonnet, have gained respectable momentum in the past few months. The company's latest fashions, DeepSeek-V3 and DeepSeek-R1, have additional solidified its place as a disruptive drive. Welcome to this subject of Recode China AI, your go-to publication for the newest AI information and analysis in China. Nvidia competitor Intel has recognized sparsity as a key avenue of research to change the state-of-the-art in the field for many years. The meteoric rise of DeepSeek when it comes to usage and popularity triggered a inventory market sell-off on Jan. 27, 2025, as buyers cast doubt on the worth of large AI distributors based in the U.S., including Nvidia. Microsoft, Meta Platforms, Oracle, Broadcom and other tech giants additionally saw significant drops as investors reassessed AI valuations. Why are traders frightened about DeepSeek? Why Choose DeepSeek Windows Download? That's certainly one of the principle reasons why the U.S. It's like buying a piano for the home; one can afford it, and there's a group eager to play music on it.
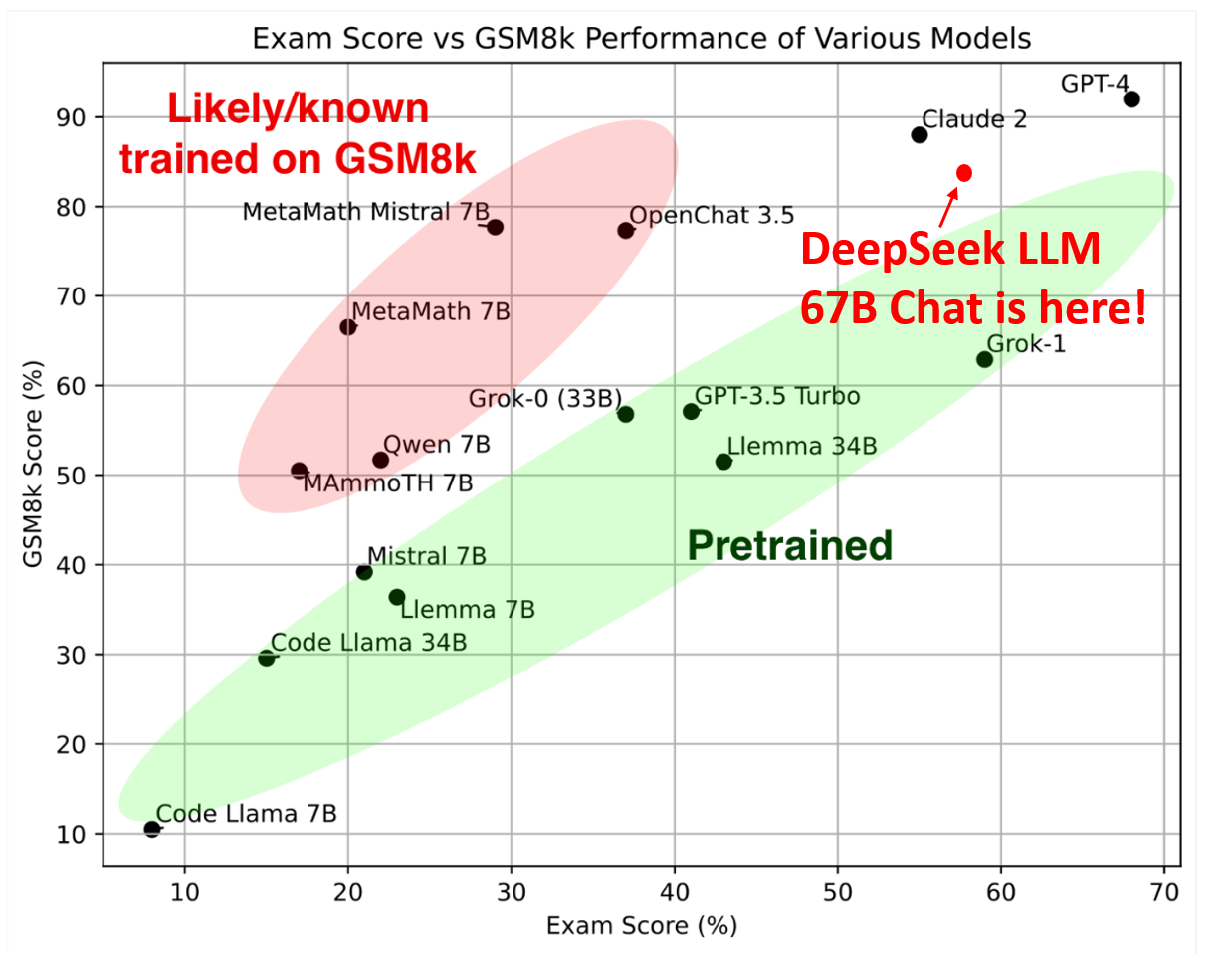 Some GPTQ clients have had issues with fashions that use Act Order plus Group Size, however this is mostly resolved now. Low tier coding work may be reduced and the high finish developers can now keep away from boiler plate kind coding problems and get back to high stage work at reengineering complicated frameworks.Yes, this sadly does imply a discount in the less skilled workforce, however frankly that is an on the entire good thing. Adapts to complicated queries using Monte Carlo Tree Search (MCTS). Abnar and team carried out their studies using a code library launched in 2023 by AI researchers at Microsoft, Google, and Stanford, called MegaBlocks. Just final month, a little-recognized Chinese company unveiled DeepSeek-V3, followed by a excessive-powered reasoning model called DeepSeek R1. As for going deeper into the stack to "escape" AI, I'd venture that is probably a non starter because the deeper you go the extra constrained the domain is, so your escape strategy relies on AI reasoning making little progress, the place AI reasoning has all the time been more successful in smaller well defined spaces. To allow fast iterations on deep studying fashions, the DGX Station also connects with the NVIDIA GPU Cloud Deep Learning Software Stack.
Some GPTQ clients have had issues with fashions that use Act Order plus Group Size, however this is mostly resolved now. Low tier coding work may be reduced and the high finish developers can now keep away from boiler plate kind coding problems and get back to high stage work at reengineering complicated frameworks.Yes, this sadly does imply a discount in the less skilled workforce, however frankly that is an on the entire good thing. Adapts to complicated queries using Monte Carlo Tree Search (MCTS). Abnar and team carried out their studies using a code library launched in 2023 by AI researchers at Microsoft, Google, and Stanford, called MegaBlocks. Just final month, a little-recognized Chinese company unveiled DeepSeek-V3, followed by a excessive-powered reasoning model called DeepSeek R1. As for going deeper into the stack to "escape" AI, I'd venture that is probably a non starter because the deeper you go the extra constrained the domain is, so your escape strategy relies on AI reasoning making little progress, the place AI reasoning has all the time been more successful in smaller well defined spaces. To allow fast iterations on deep studying fashions, the DGX Station also connects with the NVIDIA GPU Cloud Deep Learning Software Stack.
This exceptional performance, combined with the availability of DeepSeek Free, a model providing Free DeepSeek v3 access to sure options and models, makes DeepSeek accessible to a wide range of users, from students and hobbyists to professional builders. Other options embrace robust filtering choices, customizable dashboards, and real-time analytics that empower organizations to make knowledgeable selections primarily based on their findings. Wiz Research -- a group within cloud safety vendor Wiz Inc. -- printed findings on Jan. 29, 2025, about a publicly accessible again-end database spilling sensitive information onto the online -- a "rookie" cybersecurity mistake. Countries and organizations world wide have already banned DeepSeek, citing ethics, privacy and security issues inside the company. DeepSeek is a Chinese synthetic intelligence (AI) firm based mostly in Hangzhou that emerged a few years in the past from a college startup. DeepSeek modified the game by proving that state-of-the-art AI models may very well be developed at a fraction of the previous value (as low as $6 million, in accordance with the corporate). The DeepSeek chatbot was reportedly developed for a fraction of the cost of its rivals, raising questions about the future of America's AI dominance and the size of investments US companies are planning. Please visualize the department’s business information and different industry data, and use a 3-web page slices to present the evaluation outcomes and future peer benchmarking strategies and enterprise directions.
DeepSeek-V3 incorporates multi-head latent attention, which improves the model’s capacity to process data by figuring out nuanced relationships and dealing with a number of enter elements simultaneously. The flexibility to make use of solely some of the full parameters of an LLM and shut off the rest is an instance of sparsity. I agree that DeepSeek continues to prove themselves as an excellent example of engineering but the variety of job positions requiring this kind of knowledge IME is usually very very low so I'm undecided if this can be the suitable recommendation to comply with. Reward engineering is the technique of designing the incentive system that guides an AI mannequin's studying throughout training. Details apart, probably the most profound level about all this effort is that sparsity as a phenomenon isn't new in AI analysis, nor is it a brand new approach in engineering. Its success is due to a broad approach inside deep-learning types of AI to squeeze extra out of pc chips by exploiting a phenomenon generally known as "sparsity". Despite using older or downgraded chips as a consequence of U.S.
- 이전글See What Link Login Gotogel Tricks The Celebs Are Making Use Of 25.02.28
- 다음글You'll Never Guess This Best Robot Vacuum That Mops's Benefits 25.02.28
댓글목록
등록된 댓글이 없습니다.