10 Things I Want I Knew About Deepseek
페이지 정보

본문
 Personalized suggestions, demand forecasting, and inventory management are just some examples of how DeepSeek is helping retailers stay competitive in a rapidly changing market. AI is changing at a dizzying tempo and those that can adapt and leverage it stand to realize a major edge in the market. The company’s models are significantly cheaper to practice than different massive language models, which has led to a value struggle within the Chinese AI market. Yes, DeepSeek has encountered challenges, including a reported cyberattack that led the corporate to limit new user registrations temporarily. DeepSeek's first-era of reasoning models with comparable efficiency to OpenAI-o1, together with six dense models distilled from DeepSeek-R1 based mostly on Llama and Qwen. The MoE structure permits efficient inference through sparse computation, the place solely the highest six specialists are selected during inference. DeepSeek-VL2's language backbone is built on a Mixture-of-Experts (MoE) mannequin augmented with Multi-head Latent Attention (MLA).
Personalized suggestions, demand forecasting, and inventory management are just some examples of how DeepSeek is helping retailers stay competitive in a rapidly changing market. AI is changing at a dizzying tempo and those that can adapt and leverage it stand to realize a major edge in the market. The company’s models are significantly cheaper to practice than different massive language models, which has led to a value struggle within the Chinese AI market. Yes, DeepSeek has encountered challenges, including a reported cyberattack that led the corporate to limit new user registrations temporarily. DeepSeek's first-era of reasoning models with comparable efficiency to OpenAI-o1, together with six dense models distilled from DeepSeek-R1 based mostly on Llama and Qwen. The MoE structure permits efficient inference through sparse computation, the place solely the highest six specialists are selected during inference. DeepSeek-VL2's language backbone is built on a Mixture-of-Experts (MoE) mannequin augmented with Multi-head Latent Attention (MLA).
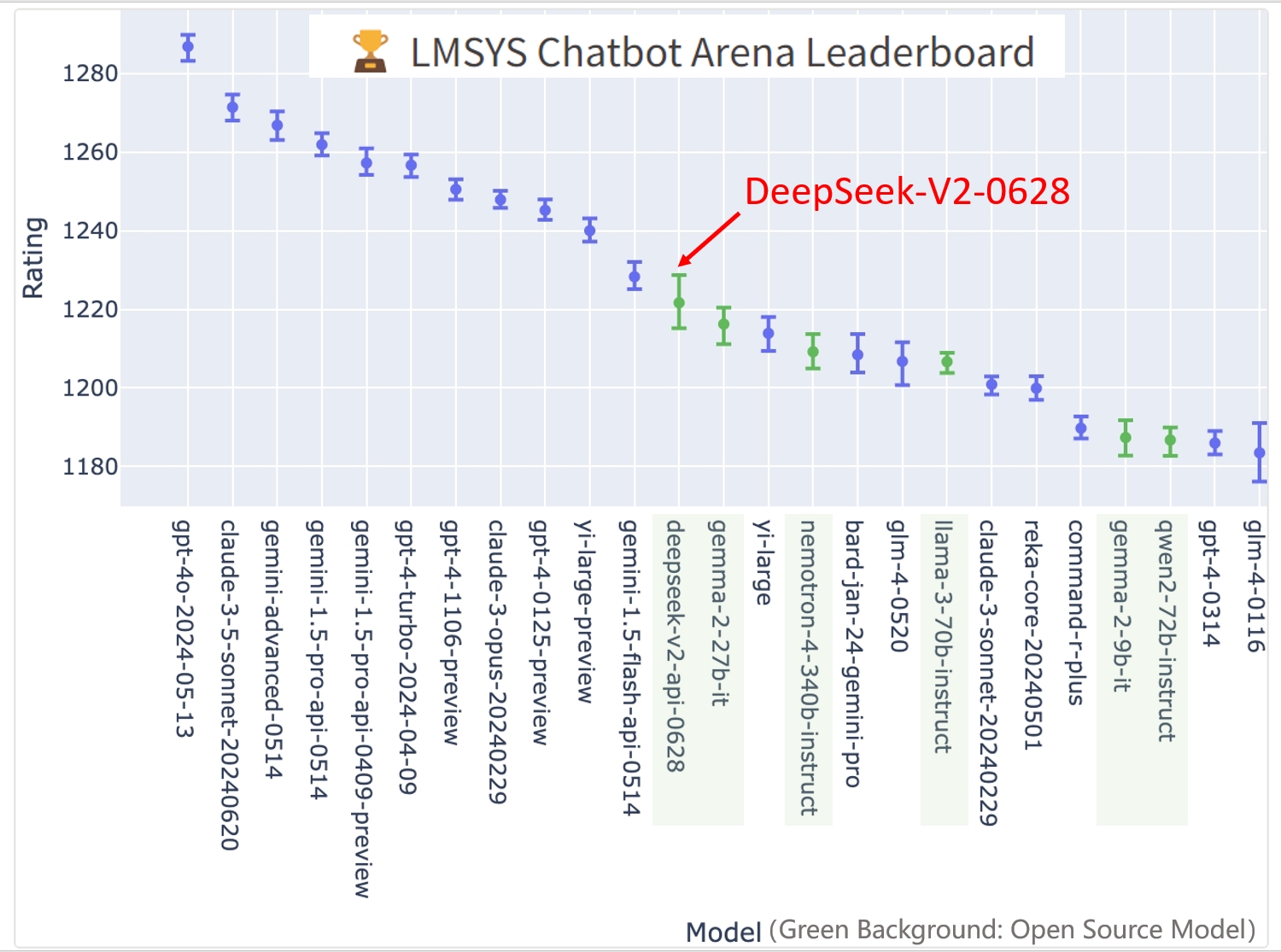
DeepSeek’s fashions are also available at no cost to researchers and commercial customers. Large Vision-Language Models (VLMs) have emerged as a transformative force in Artificial Intelligence. These differences are inclined to have enormous implications in follow - another issue of 10 might correspond to the distinction between an undergraduate and PhD talent stage - and thus companies are investing heavily in coaching these models. 2-3x of what the major US AI corporations have (for example, it's 2-3x lower than the xAI "Colossus" cluster)7. " for American tech corporations. In keeping with DeepSeek, the model exceeds OpenAI o1-preview-stage performance on established benchmarks reminiscent of AIME (American Invitational Mathematics Examination) and MATH. DeepSeek-VL2 achieves similar or higher performance than the state-of-the-art mannequin, with fewer activated parameters. Notably, on OCRBench, it scores 834, outperforming GPT-4o 736. It additionally achieves 93.3% on DocVQA for visual query-answering tasks. It has redefined benchmarks in AI, outperforming opponents while requiring just 2.788 million GPU hours for coaching. This dataset includes approximately 1.2 million caption and dialog samples. Interleaved Image-Text Data: Open-source datasets like WIT, WikiHow, and samples from OBELICS present assorted image-textual content pairs for common real-world information.
Key innovations like auxiliary-loss-free load balancing MoE,multi-token prediction (MTP), as properly a FP8 combine precision coaching framework, made it a standout. They tackle tasks like answering visible questions and document evaluation. Another key advancement is the refined imaginative and prescient language information building pipeline that boosts the overall performance and extends the model's functionality in new areas, such as precise visual grounding. MLA boosts inference effectivity by compressing the key-Value cache right into a latent vector, reducing reminiscence overhead and increasing throughput capacity. Minimizing padding reduces computational overhead and ensures extra image content is retained, improving processing effectivity. This permits DeepSeek-VL2 to handle long-context sequences extra successfully whereas sustaining computational effectivity. During training, a worldwide bias time period is introduced for every expert to enhance load balancing and optimize studying efficiency. It is a perform of ϴ (theta) which represents the parameters of the AI model we need to practice with reinforcement learning. It introduces a dynamic, high-resolution vision encoding technique and an optimized language mannequin architecture that enhances visible understanding and significantly improves the coaching and inference efficiency. On the core of DeepSeek-VL2 is a well-structured architecture built to boost multimodal understanding. DeepSeek-VL2 makes use of a 3-stage coaching pipeline that balances multimodal understanding with computational effectivity.
- 이전글instagram video indir 687 25.03.06
- 다음글Why No One Cares About Buy A Driving License 25.03.06
댓글목록
등록된 댓글이 없습니다.