5 Explanation why You are Still An Amateur At Deepseek
페이지 정보

본문
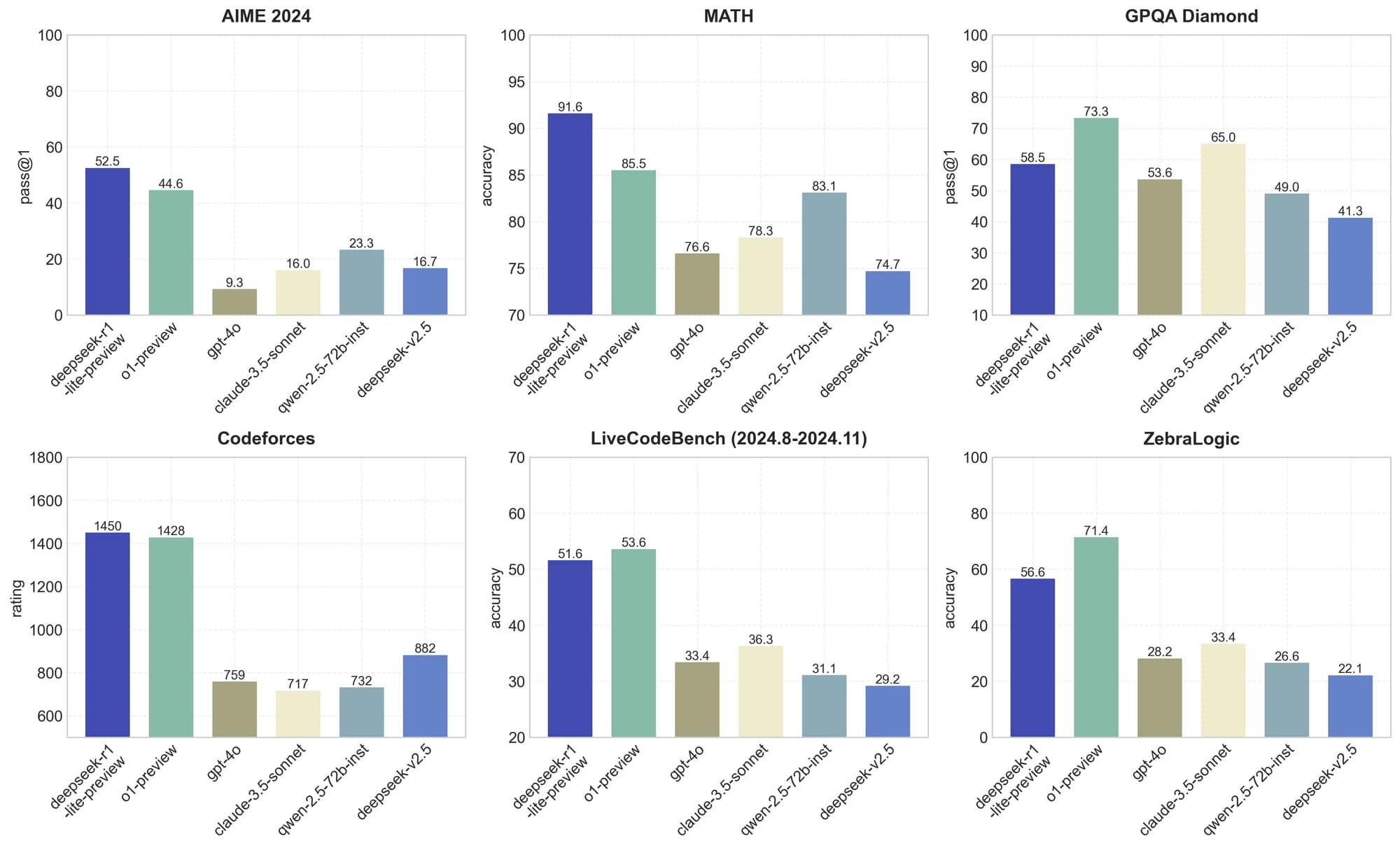 However, not like many of its US competitors, DeepSeek is open-source and Free DeepSeek Chat to make use of. As considerations about the carbon footprint of AI proceed to rise, DeepSeek’s strategies contribute to more sustainable AI practices by reducing power consumption and minimizing the usage of computational assets. MLA boosts inference efficiency by compressing the key-Value cache into a latent vector, reducing reminiscence overhead and rising throughput capability. During coaching, a global bias term is launched for each expert to enhance load balancing and optimize studying effectivity. It requires only 2.788M H800 GPU hours for its full training, together with pre-coaching, context size extension, and put up-training. Before starting coaching, the process is divided into defined stages. In this part, we are going to describe the data used in different phases of the coaching pipeline. DeepSeek-VL2 makes use of a 3-stage training pipeline that balances multimodal understanding with computational effectivity. This permits DeepSeek-VL2 to handle long-context sequences more effectively whereas sustaining computational effectivity. Let Deepseek’s AI handle the heavy lifting-so you'll be able to give attention to what matters most. DeepSeek R1 by distinction, has been launched open source and open weights, so anyone with a modicum of coding data and the hardware required can run the fashions privately, without the safeguards that apply when running the mannequin by way of DeepSeek’s API.
However, not like many of its US competitors, DeepSeek is open-source and Free DeepSeek Chat to make use of. As considerations about the carbon footprint of AI proceed to rise, DeepSeek’s strategies contribute to more sustainable AI practices by reducing power consumption and minimizing the usage of computational assets. MLA boosts inference efficiency by compressing the key-Value cache into a latent vector, reducing reminiscence overhead and rising throughput capability. During coaching, a global bias term is launched for each expert to enhance load balancing and optimize studying effectivity. It requires only 2.788M H800 GPU hours for its full training, together with pre-coaching, context size extension, and put up-training. Before starting coaching, the process is divided into defined stages. In this part, we are going to describe the data used in different phases of the coaching pipeline. DeepSeek-VL2 makes use of a 3-stage training pipeline that balances multimodal understanding with computational effectivity. This permits DeepSeek-VL2 to handle long-context sequences more effectively whereas sustaining computational effectivity. Let Deepseek’s AI handle the heavy lifting-so you'll be able to give attention to what matters most. DeepSeek R1 by distinction, has been launched open source and open weights, so anyone with a modicum of coding data and the hardware required can run the fashions privately, without the safeguards that apply when running the mannequin by way of DeepSeek’s API.
On January 20, DeepSeek, a comparatively unknown AI analysis lab from China, launched an open source model that’s shortly become the talk of the town in Silicon Valley. During this section, the language model stays frozen. Vision-Language Pre-training: Within the VL Pre-training section, all parameters are unfrozen for optimization. Initially, the imaginative and prescient encoder and vision-language adaptor MLP are educated while the language model remains mounted. Only the imaginative and prescient encoder and the adaptor are trained, utilizing a lightweight MLP connector to merge visible and textual content features. 1) is projected into the LLM’s embedding area through a two-layer MLP. In the VL Alignment stage, the focus is on bridging visual features with textual embeddings. Vision-Language Alignment: The VL Alignment section connects visible options with textual embeddings. This part adjusts mounted-resolution encoders to handle dynamic high-resolution inputs. Curious, how does Deepseek handle edge instances in API error debugging compared to GPT-four or LLaMA?
They then used that model to create a bunch of coaching knowledge to practice smaller models (the Llama and Qewn distillations). The coaching uses round 800 billion picture-textual content tokens to construct joint representations for visual and textual inputs. DeepSeek Coder contains a sequence of code language fashions skilled from scratch on both 87% code and 13% natural language in English and Chinese, with each model pre-trained on 2T tokens. To catch up on China and robotics, try our two-half series introducing the industry. The company has lately drawn attention for its AI models that claim to rival trade leaders like OpenAI. That's the place DeepSeek comes in as a big change in the AI business. On this stage, about 70% of the information comes from imaginative and prescient-language sources, and the remaining 30% is text-only knowledge sourced from the LLM pre training corpus. The text-only information comes from the LLM pretraining corpus. Pre-training information combines vision-language (VL) and textual content-only data to balance VL capabilities and check-only efficiency. This enhanced consideration mechanism contributes to DeepSeek-V3’s impressive efficiency on varied benchmarks. DeepSeek-VL2's language backbone is built on a Mixture-of-Experts (MoE) model augmented with Multi-head Latent Attention (MLA).
Visual Grounding: Data with object detection annotations guides the mannequin to locate and describe objects exactly. This part uses curated question-answer pairs from public datasets and in-home knowledge. Optical Character Recognition (OCR) Data: Public datasets comparable to LaTeX OCR and 12M RenderedText have been combined with intensive in-house OCR data masking diverse doc varieties. A complete picture captioning pipeline was used that considers OCR hints, metadata, and authentic captions as prompts to recaption the images with an in-home model. Web-to-code and Plot-to-Python Generation: In-house datasets had been expanded with open-supply datasets after response generation to enhance quality. Reasoning, Logic, and Mathematics: To enhance readability, public reasoning datasets are enhanced with detailed processes and standardized response codecs. General Visual Question-Answering: Public visible QA datasets typically suffer from quick responses, poor OCR, and hallucinations. Interleaved Image-Text Data: Open-source datasets like WIT, WikiHow, and samples from OBELICS present varied image-text pairs for common actual-world information. The VL information includes interleaved picture-textual content pairs that cover duties akin to OCR and document analysis. In order for you assist with math and reasoning duties resembling debugging and code writing, you'll be able to select the DeepSeek R1 mannequin. His ultimate aim is to develop true synthetic general intelligence (AGI), the machine intelligence able to grasp or learn tasks like a human being.
In case you loved this article as well as you desire to get more info relating to Deepseek Online chat online i implore you to visit the web-site.
- 이전글Funny Thanksgiving Memes For Dollars Seminar 25.03.06
- 다음글See What Link Daftar Gotogel Tricks The Celebs Are Making Use Of 25.03.06
댓글목록
등록된 댓글이 없습니다.