Three Ridiculous Rules About Deepseek
페이지 정보

본문
 Whether you’re a small enterprise proprietor, a knowledge analyst, or part of a large enterprise, DeepSeek can adapt to your wants. The method information on how we be taught things, or do things, from academia to business to sitting again and writing essays. Deepseek Online chat's means to process information effectively makes it a fantastic match for business automation and analytics. Perplexity now also provides reasoning with R1, DeepSeek's mannequin hosted in the US, together with its previous possibility for OpenAI's o1 main model. DeepSeek is a cutting-edge AI platform that offers advanced models for coding, mathematics, and reasoning. DeepSeek has additionally made important progress on Multi-head Latent Attention (MLA) and Mixture-of-Experts, two technical designs that make DeepSeek models more cost-effective by requiring fewer computing resources to practice. DeepSeek has emerged as a powerful contender, significantly for technical tasks and coding assistance. You need a Free DeepSeek Ai Chat, powerful AI for content creation, brainstorming, and code assistance. CriticGPT paper - LLMs are recognized to generate code that can have security points.
Whether you’re a small enterprise proprietor, a knowledge analyst, or part of a large enterprise, DeepSeek can adapt to your wants. The method information on how we be taught things, or do things, from academia to business to sitting again and writing essays. Deepseek Online chat's means to process information effectively makes it a fantastic match for business automation and analytics. Perplexity now also provides reasoning with R1, DeepSeek's mannequin hosted in the US, together with its previous possibility for OpenAI's o1 main model. DeepSeek is a cutting-edge AI platform that offers advanced models for coding, mathematics, and reasoning. DeepSeek has additionally made important progress on Multi-head Latent Attention (MLA) and Mixture-of-Experts, two technical designs that make DeepSeek models more cost-effective by requiring fewer computing resources to practice. DeepSeek has emerged as a powerful contender, significantly for technical tasks and coding assistance. You need a Free DeepSeek Ai Chat, powerful AI for content creation, brainstorming, and code assistance. CriticGPT paper - LLMs are recognized to generate code that can have security points.
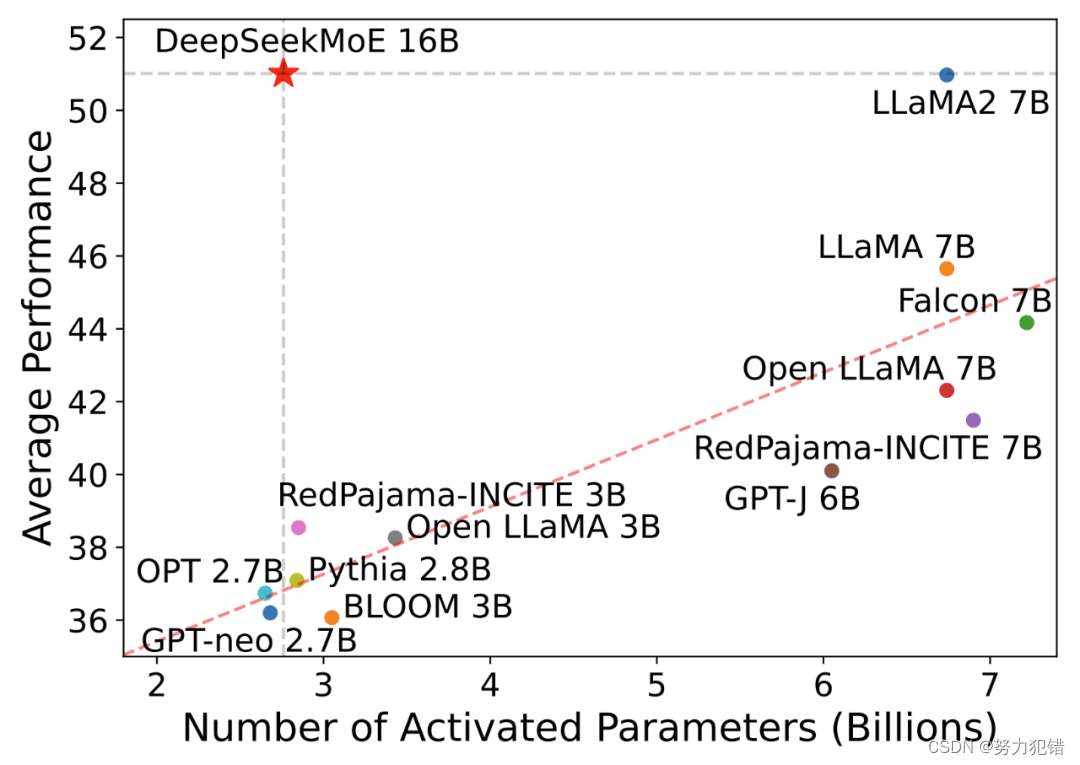 An increase in radiation on the Western United States would have devastating results on the American population. In short, CXMT is embarking upon an explosive reminiscence product capacity expansion, one that might see its global market share improve greater than ten-fold compared with its 1 percent DRAM market share in 2023. That huge capability growth translates directly into large purchases of SME, and one which the SME business discovered too engaging to show down. CodeGen is one other field the place much of the frontier has moved from research to trade and practical engineering recommendation on codegen and code brokers like Devin are only found in industry blogposts and talks relatively than research papers. RAG is the bread and DeepSeek butter of AI Engineering at work in 2024, so there are a number of business resources and practical experience you'll be anticipated to have. We recommend having working expertise with vision capabilities of 4o (including finetuning 4o imaginative and prescient), Claude 3.5 Sonnet/Haiku, Gemini 2.Zero Flash, and o1. With Gemini 2.0 also being natively voice and vision multimodal, the Voice and Vision modalities are on a clear path to merging in 2025 and beyond.
An increase in radiation on the Western United States would have devastating results on the American population. In short, CXMT is embarking upon an explosive reminiscence product capacity expansion, one that might see its global market share improve greater than ten-fold compared with its 1 percent DRAM market share in 2023. That huge capability growth translates directly into large purchases of SME, and one which the SME business discovered too engaging to show down. CodeGen is one other field the place much of the frontier has moved from research to trade and practical engineering recommendation on codegen and code brokers like Devin are only found in industry blogposts and talks relatively than research papers. RAG is the bread and DeepSeek butter of AI Engineering at work in 2024, so there are a number of business resources and practical experience you'll be anticipated to have. We recommend having working expertise with vision capabilities of 4o (including finetuning 4o imaginative and prescient), Claude 3.5 Sonnet/Haiku, Gemini 2.Zero Flash, and o1. With Gemini 2.0 also being natively voice and vision multimodal, the Voice and Vision modalities are on a clear path to merging in 2025 and beyond.
The unique authors have began Contextual and have coined RAG 2.0. Modern "table stakes" for RAG - HyDE, chunking, rerankers, multimodal data are better offered elsewhere. Multimodal versions of MMLU (MMMU) and SWE-Bench do exist. See also SWE-Agent, SWE-Bench Multimodal and the Konwinski Prize. SWE-Bench paper (our podcast) - after adoption by Anthropic, Devin and OpenAI, in all probability the very best profile agent benchmark5 at present (vs WebArena or SWE-Gym). SWE-Bench is more famous for coding now, however is costly/evals agents fairly than fashions. NIM microservices advance a model’s efficiency, enabling enterprise AI agents to run sooner on GPU-accelerated systems. This capability is especially worthwhile for software program builders working with intricate systems or professionals analyzing massive datasets. ✅ Enhances Learning - Students and professionals can use it to realize information, make clear doubts, and enhance their skills. DeepSeek is a complicated AI-powered platform that makes use of state-of-the-artwork machine studying (ML) and natural language processing (NLP) applied sciences to ship intelligent options for data analysis, automation, and resolution-making. Compressor summary: This paper introduces Bode, a fantastic-tuned LLaMA 2-based model for Portuguese NLP duties, which performs higher than existing LLMs and is freely out there. Compressor abstract: The Locally Adaptive Morphable Model (LAMM) is an Auto-Encoder framework that learns to generate and manipulate 3D meshes with native control, attaining state-of-the-artwork performance in disentangling geometry manipulation and reconstruction.
Compressor abstract: SPFormer is a Vision Transformer that makes use of superpixels to adaptively partition pictures into semantically coherent areas, reaching superior performance and explainability compared to conventional strategies. Compressor summary: The paper proposes a technique that uses lattice output from ASR methods to improve SLU tasks by incorporating phrase confusion networks, enhancing LLM's resilience to noisy speech transcripts and robustness to various ASR performance conditions. R1 specifically has 671 billion parameters throughout multiple expert networks, but solely 37 billion of these parameters are required in a single "forward move," which is when an input is passed by way of the model to generate an output. The Hangzhou-primarily based firm mentioned in a WeChat submit on Thursday that its namesake LLM, DeepSeek V3, comes with 671 billion parameters and trained in round two months at a price of US$5.Fifty eight million, utilizing considerably fewer computing resources than models developed by greater tech companies. This stage of transparency is a significant draw for these involved concerning the "black field" nature of some AI fashions. Consistency Models paper - this distillation work with LCMs spawned the fast draw viral moment of Dec 2023. These days, up to date with sCMs.
If you loved this information and you would certainly such as to obtain more information relating to Free Deepseek Online Chat kindly visit the web page.
- 이전글Shocking Information about Upcoming Horse Race Exposed 25.03.07
- 다음글delta-9-thc-20mg-gummies-variety-gift-pack 25.03.07
댓글목록
등록된 댓글이 없습니다.