The best way to Deal With(A) Very Dangerous Deepseek China Ai
페이지 정보

본문
 Ask DeepSeek’s newest AI model, unveiled final week, to do issues like explain who is winning the AI race, summarize the most recent govt orders from the White House or inform a joke and a user will get related solutions to those spewed out by American-made rivals OpenAI’s GPT-4, Meta’s Llama or Google’s Gemini. I extremely suggest enjoying it (or different variations, comparable to Intelligence Rising) to anybody who will get the chance, and am very curious to watch more skilled individuals (as in NatSec varieties) play. DeepSeek exhibits that open-source labs have change into far more efficient at reverse-engineering. "DeepSeek clearly doesn’t have entry to as a lot compute as U.S. The U.S. strategy cannot rely on the assumption that China will fail to overcome restrictions. If the space between New York and Los Angeles is 2,800 miles, at what time will the two trains meet? Based on studies from the company’s disclosure, DeepSeek bought 10,000 Nvidia A100 chips, which was first launched in 2020, and two generations prior to the current Blackwell chip from Nvidia, before the A100s were restricted in late 2023 for sale to China.
Ask DeepSeek’s newest AI model, unveiled final week, to do issues like explain who is winning the AI race, summarize the most recent govt orders from the White House or inform a joke and a user will get related solutions to those spewed out by American-made rivals OpenAI’s GPT-4, Meta’s Llama or Google’s Gemini. I extremely suggest enjoying it (or different variations, comparable to Intelligence Rising) to anybody who will get the chance, and am very curious to watch more skilled individuals (as in NatSec varieties) play. DeepSeek exhibits that open-source labs have change into far more efficient at reverse-engineering. "DeepSeek clearly doesn’t have entry to as a lot compute as U.S. The U.S. strategy cannot rely on the assumption that China will fail to overcome restrictions. If the space between New York and Los Angeles is 2,800 miles, at what time will the two trains meet? Based on studies from the company’s disclosure, DeepSeek bought 10,000 Nvidia A100 chips, which was first launched in 2020, and two generations prior to the current Blackwell chip from Nvidia, before the A100s were restricted in late 2023 for sale to China.
Earlier this month, OpenAI previewed its first actual try at a common function AI agent called Operator, which seems to have been overshadowed by the DeepSeek focus. But OpenAI does have the main AI brand in ChatGPT, one thing that needs to be helpful as more individuals search to interact with synthetic intelligence. It was additionally just a bit bit emotional to be in the same type of ‘hospital’ because the one which gave birth to Leta AI and GPT-3 (V100s), ChatGPT, GPT-4, DALL-E, and much more. I wish to carry on the ‘bleeding edge’ of AI, but this one got here faster than even I used to be ready for. That is considered one of my favorite methods to make use of AI-to clarify arduous topics in simple terms. Tech giants are dashing to construct out huge AI information centers, with plans for some to use as much electricity as small cities. Later in this version we take a look at 200 use cases for submit-2020 AI. As a reference, let's take a look at how OpenAI's ChatGPT compares to DeepSeek. It is interesting to see that 100% of these corporations used OpenAI fashions (in all probability via Microsoft Azure OpenAI or Microsoft Copilot, rather than ChatGPT Enterprise).
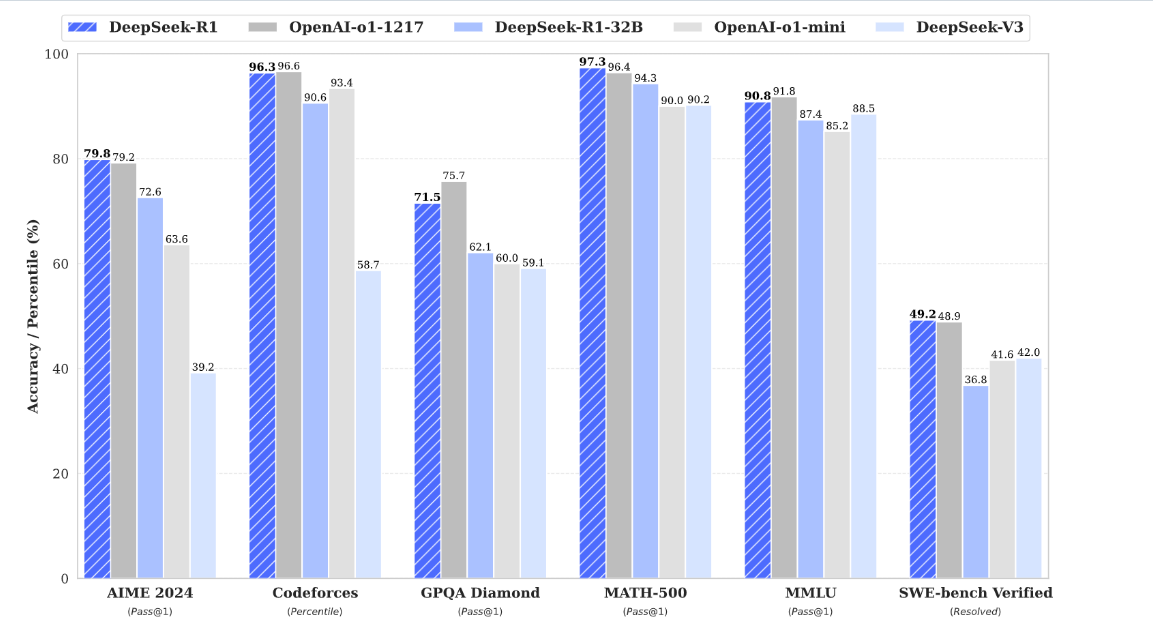
Ms Rosenberg stated the shock and subsequent rally of tech stocks on Wall Street may very well be a constructive improvement, after the worth of AI-linked companies saw months of exponential progress. AI labs achieve can now be erased in a matter of months. Kavukcuoglu, Koray. "Gemini 2.0 is now accessible to everybody". Cerebras FLOR-6.3B, Allen AI OLMo 7B, Google TimesFM 200M, AI Singapore Sea-Lion 7.5B, ChatDB Natural-SQL-7B, Brain GOODY-2, Alibaba Qwen-1.5 72B, Google DeepMind Gemini 1.5 Pro MoE, Google DeepMind Gemma 7B, Reka AI Reka Flash 21B, Reka AI Reka Edge 7B, Apple Ask 20B, Reliance Hanooman 40B, Mistral AI Mistral Large 540B, Mistral AI Mistral Small 7B, ByteDance 175B, ByteDance 530B, HF/ServiceNow StarCoder 2 15B, HF Cosmo-1B, SambaNova Samba-1 1.4T CoE. Anthropic Claude three Opus 2T, SRIBD/CUHK Apollo 7B, Inflection AI Inflection-2.5 1.2T, Stability AI Stable Beluga 2.5 70B, Fudan University AnyGPT 7B, DeepSeek-AI DeepSeek-VL 7B, Cohere Command-R 35B, Covariant RFM-1 8B, Apple MM1, RWKV RWKV-v5 EagleX 7.52B, Independent Parakeet 378M, Rakuten Group RakutenAI-7B, Sakana AI EvoLLM-JP 10B, Stability AI Stable Code Instruct 3B, MosaicML DBRX 132B MoE, AI21 Jamba 52B MoE, xAI Grok-1.5 314B, Alibaba Qwen1.5-MoE-A2.7B 14.3B MoE. Benchmark checks indicate that DeepSeek-V3 outperforms fashions like Llama 3.1 and Qwen 2.5, whereas matching the capabilities of GPT-4o and Claude 3.5 Sonnet.
DeepSeek-V3 demonstrates aggressive performance, standing on par with top-tier fashions equivalent to LLaMA-3.1-405B, GPT-4o, and Claude-Sonnet 3.5, whereas significantly outperforming Qwen2.5 72B. Moreover, DeepSeek-V3 excels in MMLU-Pro, a more challenging instructional data benchmark, the place it carefully trails Claude-Sonnet 3.5. On MMLU-Redux, a refined model of MMLU with corrected labels, DeepSeek-V3 surpasses its friends. This strategy ensures higher performance while utilizing fewer sources. While we strive for accuracy and timeliness, due to the experimental nature of this technology we can not assure that we’ll all the time achieve success in that regard. DeepSeek's mission centers on advancing synthetic normal intelligence (AGI) through open-supply analysis and growth, aiming to democratize AI know-how for each commercial and educational applications. What are DeepSeek's AI models? DeepSeek's AI fashions can be found by means of its official website, the place users can access the DeepSeek-V3 model free Deep seek of charge. Additionally, the DeepSeek app is obtainable for download, offering an all-in-one AI device for customers. Here's a deeper dive into how to hitch DeepSeek. DeepSeek Releases VL2, a Series of MoE Vision-Language Models. The DeepSeek models weren't the identical (R1 was too large to check locally, so we used a smaller version), however across all three categories, we recognized tactics regularly utilized in Chinese public opinion steering.
If you have any sort of inquiries relating to where and how you can utilize deepseek français, you can call us at the site.
- 이전글клининг уборка квартир 25.03.22
- 다음글стоимость уборки квартиры после ремонта 25.03.22
댓글목록
등록된 댓글이 없습니다.