Life, Death And Deepseek
페이지 정보

본문
 Where can I get assist if I face issues with DeepSeek Windows? It’s self hosted, may be deployed in minutes, and works instantly with PostgreSQL databases, schemas, and tables without further abstractions. Mathesar is a web software that makes working with PostgreSQL databases each simple and highly effective. DeepSeek API makes it straightforward to combine superior AI models, together with DeepSeek R1, into your utility with familiar API formats, enabling easy development. Configuration: Configure the application as per the documentation, which may contain setting surroundings variables, configuring paths, and adjusting settings to optimize performance. This minimizes efficiency loss without requiring massive redundancy. DeepSeek's innovation right here was creating what they call an "auxiliary-loss-free" load balancing technique that maintains efficient expert utilization with out the same old performance degradation that comes from load balancing. DeepSeek cracked this downside by growing a intelligent system that breaks numbers into small tiles for activations and blocks for weights, and strategically uses high-precision calculations at key points in the network.
Where can I get assist if I face issues with DeepSeek Windows? It’s self hosted, may be deployed in minutes, and works instantly with PostgreSQL databases, schemas, and tables without further abstractions. Mathesar is a web software that makes working with PostgreSQL databases each simple and highly effective. DeepSeek API makes it straightforward to combine superior AI models, together with DeepSeek R1, into your utility with familiar API formats, enabling easy development. Configuration: Configure the application as per the documentation, which may contain setting surroundings variables, configuring paths, and adjusting settings to optimize performance. This minimizes efficiency loss without requiring massive redundancy. DeepSeek's innovation right here was creating what they call an "auxiliary-loss-free" load balancing technique that maintains efficient expert utilization with out the same old performance degradation that comes from load balancing. DeepSeek cracked this downside by growing a intelligent system that breaks numbers into small tiles for activations and blocks for weights, and strategically uses high-precision calculations at key points in the network.
 Dynamic Routing Architecture: A reconfigurable community reroutes information round defective cores, leveraging redundant pathways and spare cores. NVIDIA (2022) NVIDIA. Improving community performance of HPC systems using NVIDIA Magnum IO NVSHMEM and GPUDirect Async. Cerebras Systems has wrote an article on semiconductor manufacturing by reaching viable yields for wafer-scale processors regardless of their massive size, challenging the longstanding belief that larger chips inherently suffer from decrease yields. Abstract: Reinforcement learning from human feedback (RLHF) has grow to be an necessary technical and storytelling tool to deploy the newest machine learning systems. Reinforcement studying (RL): The reward mannequin was a process reward mannequin (PRM) trained from Base in accordance with the Math-Shepherd methodology. Tensorgrad is a tensor & deep learning framework. MLX-Examples comprises a wide range of standalone examples utilizing the MLX framework. Nvidia H100: This 814mm² GPU accommodates 144 streaming multiprocessors (SMs), but only 132 are active in industrial merchandise(1/12 is defective). To be particular, during MMA (Matrix Multiply-Accumulate) execution on Tensor Cores, intermediate outcomes are accumulated utilizing the restricted bit width. There is a wonderful blog publish(albeit a bit lengthy) that details about a few of the bull, base and bear circumstances for NVIDIA by going by means of the technical panorama, opponents and what that might imply and appear like in future for NVIDIA.
Dynamic Routing Architecture: A reconfigurable community reroutes information round defective cores, leveraging redundant pathways and spare cores. NVIDIA (2022) NVIDIA. Improving community performance of HPC systems using NVIDIA Magnum IO NVSHMEM and GPUDirect Async. Cerebras Systems has wrote an article on semiconductor manufacturing by reaching viable yields for wafer-scale processors regardless of their massive size, challenging the longstanding belief that larger chips inherently suffer from decrease yields. Abstract: Reinforcement learning from human feedback (RLHF) has grow to be an necessary technical and storytelling tool to deploy the newest machine learning systems. Reinforcement studying (RL): The reward mannequin was a process reward mannequin (PRM) trained from Base in accordance with the Math-Shepherd methodology. Tensorgrad is a tensor & deep learning framework. MLX-Examples comprises a wide range of standalone examples utilizing the MLX framework. Nvidia H100: This 814mm² GPU accommodates 144 streaming multiprocessors (SMs), but only 132 are active in industrial merchandise(1/12 is defective). To be particular, during MMA (Matrix Multiply-Accumulate) execution on Tensor Cores, intermediate outcomes are accumulated utilizing the restricted bit width. There is a wonderful blog publish(albeit a bit lengthy) that details about a few of the bull, base and bear circumstances for NVIDIA by going by means of the technical panorama, opponents and what that might imply and appear like in future for NVIDIA.
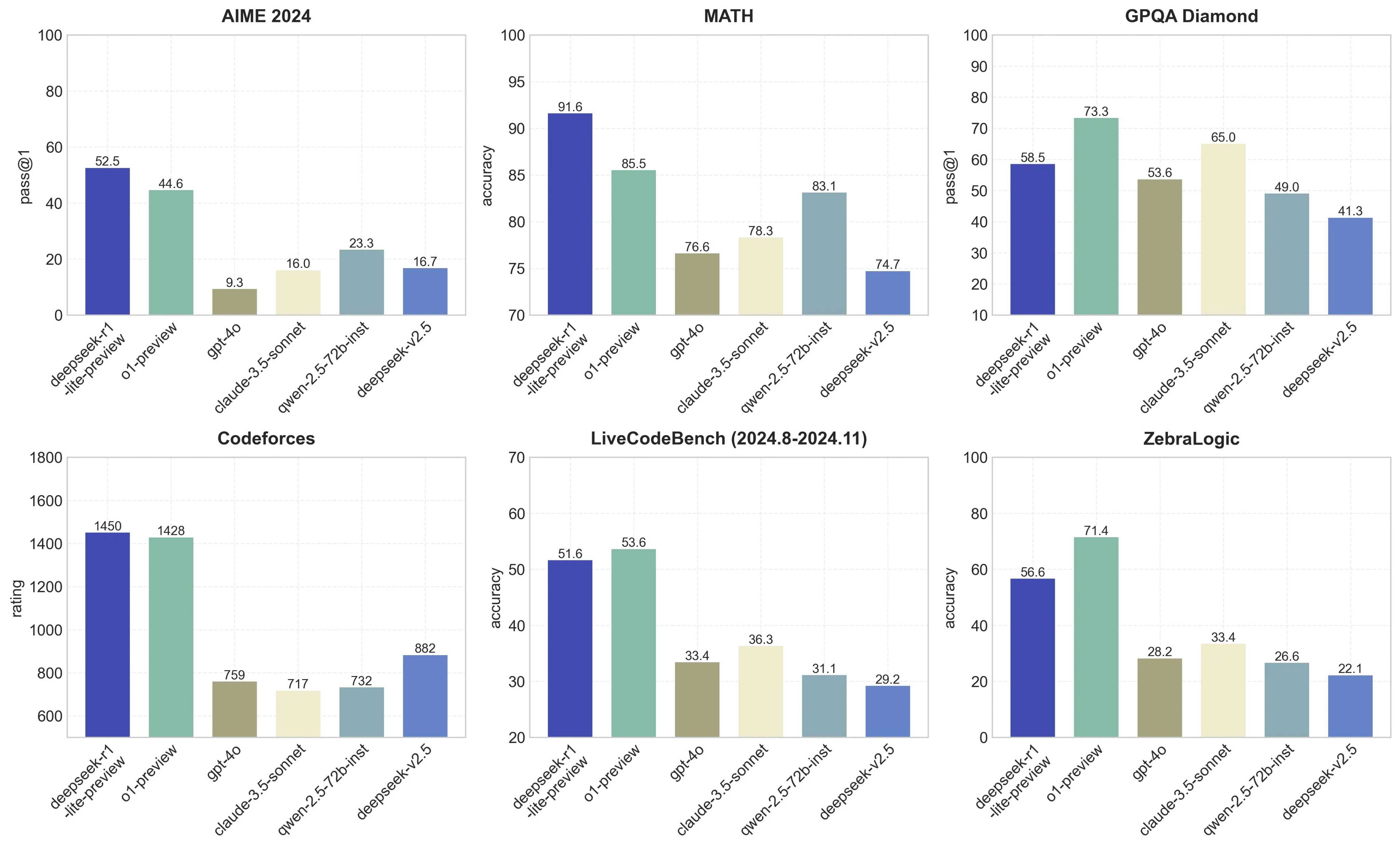
Skipping SFT: Applying RL on to the bottom mannequin. 1. Download the model weights from Hugging Face, and put them into /path/to/DeepSeek-V3 folder. Those who use the R1 model in DeepSeek’s app may also see its "thought" course of as it answers questions. Download and install the app in your gadget. The subsequent set of recent languages are coming in an April software program update. We then set the stage with definitions, problem formulation, knowledge assortment, and different common math used in the literature. Unlike different labs that train in excessive precision after which compress later (shedding some quality in the method), DeepSeek's native FP8 approach means they get the huge memory financial savings with out compromising performance. PDFs (even ones that require OCR), Word recordsdata, etc; it even means that you can submit an audio file and automatically transcribes it with the Whisper mannequin, cleans up the resulting textual content, and then computes the embeddings for it. To keep away from wasting computation, these embeddings are cached in SQlite and retrieved if they've already been computed before. Note: Best results are shown in bold. Note: All models are evaluated in a configuration that limits the output size to 8K. Benchmarks containing fewer than 1000 samples are tested multiple times using various temperature settings to derive sturdy ultimate results.
Then, relying on the nature of the inference request, you may intelligently route the inference to the "expert" models inside that assortment of smaller fashions that are most in a position to reply that question or solve that task. The growing usage of chain of thought (CoT) reasoning marks a new period for big language models. Transformer language model coaching. Bidirectional language understanding with BERT. They've one cluster that they're bringing online for Anthropic that options over 400k chips. You are now ready to sign up. With a quick and straightforward setup process, you'll immediately get access to a veritable "Swiss Army Knife" of LLM related instruments, all accessible by way of a handy Swagger UI and able to be built-in into your individual purposes with minimal fuss or configuration required. Most LLMs write code to access public APIs very effectively, but struggle with accessing non-public APIs. Well, instead of making an attempt to battle Nvidia head-on by using a similar approach and making an attempt to match the Mellanox interconnect technology, Cerebras has used a radically revolutionary method to do an finish-run across the interconnect downside: inter-processor bandwidth becomes a lot less of an issue when every thing is working on the identical tremendous-sized chip.
- 이전글시알리스 100mg정품구입 녹내장비아그라, 25.03.22
- 다음글Customer Testimonies on the Performance of Provadent 25.03.22
댓글목록
등록된 댓글이 없습니다.