9 Cut-Throat Deepseek Ai News Tactics That Never Fails
페이지 정보

본문
Performance: DeepSeek-V2 outperforms DeepSeek 67B on almost all benchmarks, achieving stronger efficiency whereas saving on coaching prices, decreasing the KV cache, and rising the utmost generation throughput. Economical Training and Efficient Inference: In comparison with its predecessor, DeepSeek-V2 reduces training prices by 42.5%, reduces the KV cache measurement by 93.3%, and increases most era throughput by 5.76 occasions. Strong Performance: DeepSeek-V2 achieves high-tier performance amongst open-supply fashions and becomes the strongest open-source MoE language model, outperforming its predecessor DeepSeek 67B while saving on coaching costs. Economical Training: Training DeepSeek-V2 costs 42.5% lower than coaching DeepSeek 67B, attributed to its revolutionary architecture that includes a sparse activation method, decreasing the total computational demand during training. Alignment with Human Preferences: DeepSeek-V2 is aligned with human preferences utilizing online Reinforcement Learning (RL) framework, which considerably outperforms the offline strategy, and Supervised Fine-Tuning (SFT), attaining high-tier performance on open-ended dialog benchmarks. This permits for extra environment friendly computation whereas maintaining high efficiency, demonstrated through high-tier results on numerous benchmarks.
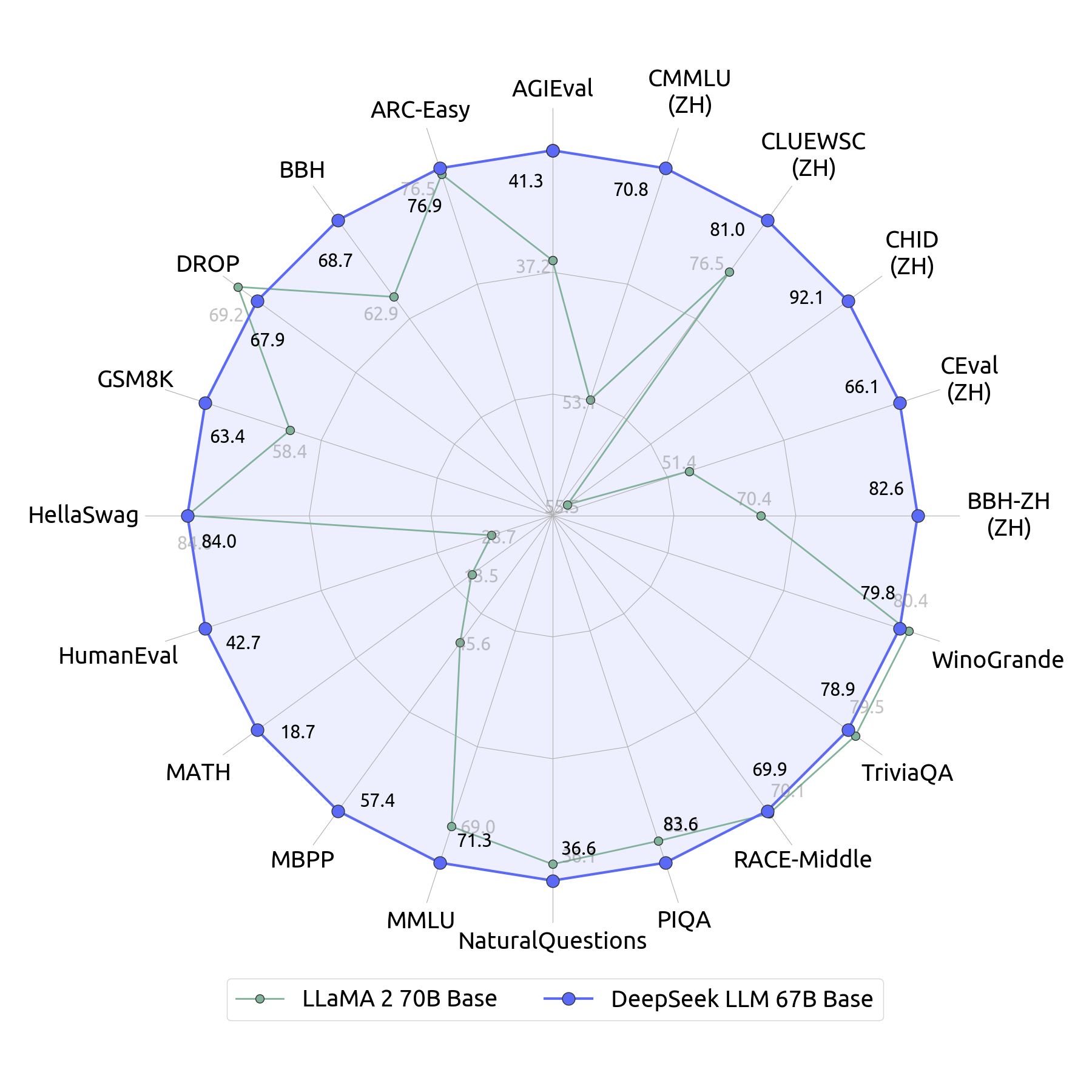 Mixtral 8x22B: DeepSeek-V2 achieves comparable or better English efficiency, aside from a couple of specific benchmarks, and outperforms Mixtral 8x22B on MMLU and Chinese benchmarks. Qwen1.5 72B: DeepSeek-V2 demonstrates overwhelming advantages on most English, code, and math benchmarks, and is comparable or higher on Chinese benchmarks. The good court system, built with the deep involvement of China's tech giants, would also pass an excessive amount of energy into the arms of some technical consultants who wrote the code, developed algorithms or supervised the database. This collaboration has led to the creation of AI fashions that eat significantly less computing energy. How does DeepSeek-V2 compare to its predecessor and different competing models? The importance of DeepSeek-V2 lies in its skill to deliver sturdy performance whereas being cost-effective and environment friendly. LLaMA3 70B: Despite being trained on fewer English tokens, DeepSeek-V2 exhibits a slight gap in basic English capabilities but demonstrates comparable code and math capabilities, and significantly higher efficiency on Chinese benchmarks. Chat Models: DeepSeek-V2 Chat (SFT) and (RL) surpass Qwen1.5 72B Chat on most English, math, and code benchmarks.
Mixtral 8x22B: DeepSeek-V2 achieves comparable or better English efficiency, aside from a couple of specific benchmarks, and outperforms Mixtral 8x22B on MMLU and Chinese benchmarks. Qwen1.5 72B: DeepSeek-V2 demonstrates overwhelming advantages on most English, code, and math benchmarks, and is comparable or higher on Chinese benchmarks. The good court system, built with the deep involvement of China's tech giants, would also pass an excessive amount of energy into the arms of some technical consultants who wrote the code, developed algorithms or supervised the database. This collaboration has led to the creation of AI fashions that eat significantly less computing energy. How does DeepSeek-V2 compare to its predecessor and different competing models? The importance of DeepSeek-V2 lies in its skill to deliver sturdy performance whereas being cost-effective and environment friendly. LLaMA3 70B: Despite being trained on fewer English tokens, DeepSeek-V2 exhibits a slight gap in basic English capabilities but demonstrates comparable code and math capabilities, and significantly higher efficiency on Chinese benchmarks. Chat Models: DeepSeek-V2 Chat (SFT) and (RL) surpass Qwen1.5 72B Chat on most English, math, and code benchmarks.
DeepSeek-V2’s Coding Capabilities: Users report optimistic experiences with DeepSeek-V2’s code generation abilities, significantly for Python. Which means the model’s code and architecture are publicly accessible, and anyone can use, modify, and distribute them freely, topic to the phrases of the MIT License. In case you do or say one thing that the issuer of the digital forex you’re utilizing doesn’t like, your means to buy food, gas, clothes or anything can been revoked. DeepSeek claims that it trained its models in two months for $5.6 million and using fewer chips than typical AI fashions. Despite the safety and legal implications of utilizing ChatGPT at work, AI applied sciences are still in their infancy and are here to remain. Text-to-Speech (TTS) and Speech-to-Text (STT) applied sciences enable voice interactions with the conversational agent, enhancing accessibility and user experience. This accessibility expands the potential person base for the model. Censorship and Alignment with Socialist Values: DeepSeek-V2’s system prompt reveals an alignment with "socialist core values," resulting in discussions about censorship and potential biases.
The outcomes spotlight QwQ-32B’s efficiency in comparison to other main fashions, including DeepSeek-R1-Distilled-Qwen-32B, DeepSeek-R1-Distilled-Llama-70B, o1-mini, and the unique DeepSeek Ai Chat-R1. On January 30, Nvidia, the Santa Clara-primarily based designer of the GPU chips that make AI models possible, introduced it can be deploying DeepSeek-R1 on its own "NIM" software program. The flexibility to run giant fashions on extra readily available hardware makes DeepSeek-V2 a beautiful possibility for groups with out extensive GPU resources. Large MoE Language Model with Parameter Efficiency: DeepSeek-V2 has a complete of 236 billion parameters, however solely activates 21 billion parameters for every token. DeepSeek-V2 is a strong, open-source Mixture-of-Experts (MoE) language mannequin that stands out for its economical training, efficient inference, and top-tier performance throughout varied benchmarks. Robust Evaluation Across Languages: It was evaluated on benchmarks in each English and Chinese, indicating its versatility and strong multilingual capabilities. The startup was based in 2023 in Hangzhou, China and released its first AI giant language model later that year. The database included some DeepSeek chat historical past, backend particulars and technical log information, in keeping with Wiz Inc., the cybersecurity startup that Alphabet Inc. sought to purchase for $23 billion last year.
Here is more about Free DeepSeek V3 visit our web page.
- 이전글мойка окон в квартире цены 25.03.23
- 다음글비아그라정품구입방법 프릴리지구매대행, 25.03.23
댓글목록
등록된 댓글이 없습니다.